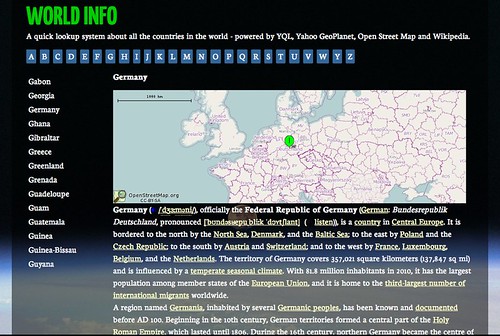
So here’s my submission: an interface to get information about any country on this planet in under 5K:
I got the idea last Thursday during Pub Standards in London when someone asked me if it is possible to get information about all the countries in the world using YQL. The main interest was not only to get the names but also the bounding box information in order to display maps with the right zoom level. And it is, all you need to do in YQL is the following:
select name,boundingBox from geo.places.children(0) where
parent_woeid=1 and placetype="country" | sort(field="name")
This gets all the children of the entry with the WOEID of 1 (Earth, that is) in the GeoPlanet dataset that are a country and sorts them alphabetically for you.
Each of the results comes with bounding box information which you then can use to display a map with the Open Streetmap static image API (or any other provider). For example:
var image = 'http://pafciu17.dev.openstreetmap.org/?module=map&bbox='+
bb.boundingBox.southWest.longitude+','+
bb.boundingBox.northEast.latitude+','+
bb.boundingBox.northEast.longitude+','+
bb.boundingBox.southWest.latitude+
'&width=500&height=250';
The last piece to the puzzle was where to get country information from and of course the easiest is Wikipedia. Every country web site in Wikipedia has a info table about it which turned out to be too much of a pain to clean up so all I did was to scrape the first three paragraphs following this table with YQL:
select * from html where
url="http://en.wikipedia.org/wiki/Christmas_Islands"
and xpath="//table/following-sibling::p" limit 3
The rest, as they say, is history. I built the system in all in all 2 hours and now I spent some time to clean it up and spice it up:
As the first loading of the data takes a long time I use HTML5 local storage to cache the country information. This means you only have to wait once and subsequently it’ll be much faster.
If I were to build this as a real product I would cache the results on a server rather than hammering the APIs every time a user comes along – as the information doesn’t change much this makes much more sense. I will probably release a PHP version of that soon. For now, this is what we have.
Yesterday night Mozilla invited developers to the Hub in King’s Cross, London to learn about Add-ons and the future of Firefox.
Nick Nguyen on Add-ons
The evening started with Nick Nguyen with Mozilla giving us an overview of the reach and numbers of extensions that are currently available for Firefox and Thunderbird. Some of the numbers were:
To date there were 2 billion downloads
only 40% of the add-ons were created in the US (followed by Germany) – this is the same in the Yahoo Developer Network, the US is the main market but developers are elsewhere
40% of Firefox users have add-ons (8 is the most common amount of installs)
People created 588 Themes
1054 Search Engines were added to Firefox
Overall the community created 4441 Extensions
The surprising number was that people created 156,147 Personas (skins for Firefox)
This, according to Nick, makes the Mozilla stack the “richest extensions platform”.
The move to Jetpack
Nick then went on to explain the changes in add-on architecture, especially the move from XUL based add-ons to Jetpack. Whilst the old school XUL path still yields the most powerful results, Jetpack is the preferred way to build for the future, because of a few reasons:
user don’t need to restart the browser to install them
Nick then explained some of the options for promoting your add-ons. Promotion is possible for targeted markets and promoted add-ons normally tend to get 5-10k downloads/day. Firefox 4 will have add-ons in a tab – full screen and featured instead of the currently somewhat cumbersome add-on manager.
The Rock your Firefox blog describes the story of add-ons and how it improves people’s lives. It is an editorial servers for developers. Featured add-ons get 2-3 days exposure and ten-thousands of downloads.
The Mozilla contributions program allows people to donate money for developers. So far 500 add-ons (12% overall) received money from the programme. It has run for 10 months and so far raised $90,000.
The next step for Mozilla now will be an add-on Marketplace – which is a store for add-ons. They want to try it out and see how it will work out. In a survey conducted amongst the add-on developer community 3 out of 4 developers like the idea of reaching 100 million active add-on users and sell their add-ons for 1 to 5 dollars. Mozilla is very outspoken about never to consider a DRM model and consider fair pricing the better way to fight piracy. The store will accept Paypal and all major credit cards. One of the key requirements is support for non US developers and the store encourages free add-ons that feature more options in the paid versions – much like the Android market does now.
Overall Mozilla like to see their planned app store not like a mall but like an organic farmers market.
Justin Scott – on making add-ons people will love
Justin Scott talked us through some of the steps how to build a really good add-on and explained some of the pitfalls to avoid. His talk was structured in three stages of add-on deployment: building, marketing and listening.
Building your add-on
One of the biggest feedback items Mozilla users gave in a survey about add-on happiness is that they are expecting a clean first run of the add-on. things people didn’t like at all were:
Add-ons that require registration
modal dialogs and wizards
asking to change the user’s settings
pages that pop up after updating and changelogs
If you for example click on a link in an email you don’t want your Firefox to open a different pages as an add-on needed upgrading. This was one of the main reasons why the new add-on manager in Firefox 4 will not pop up any longer but will be much more discreet.
A few tips for good deployment:
Put your dialogs on the first run page or have it user triggered instead of forcing users to change setting when the add-on gets upgraded
Don’t clutter the UI - instead try to integrate your extension with the UI as if they are a part of Firefox.
Stick to one way of showing the extension and allow the user to choose where they want to see it – as an icon in the toolbar, on the bottom right, as a right-click extension and so on.
One bad example Justin showed was the Delicious extension which adds 7 logos to the Firefox chrome in different areas.
The next point Justin brought up is that it is very important to earn and keep the user’s trust. He explained some of the main mistakes that add-on developers do:
change the browser’s search provider for ad sales
replace ads on websites with own ads
install other add-ons with the one you agreed to install
This lead to the “no surprises policy” of Mozilla:
Every add-on needs to have a full disclosure of what it does (including the changes mentioned above)
Users have to opt-in to these changes
Changes have to revert on uninstall
All changes have to be included from the start and not on the second or third run
Some tips to avoid annoyances are:
Choose a core functionality and stick with it – don’t change the functionality on updates
Have a clear privacy policy – install the proper way – not with .exe.
Stay current: update compatibility before the next release, avoid conflicts with other add-ons, leverage new features like restartless add-ons, larger icons and mobile support
Build fast add-ons. Your add-on should not delay the start up of Firefox. Mozilla are working on tools to measure performance and tell developers how to change them.
Marketing for your add-on
Next up were some of the ideas how to market your add-on. Pretty basic advice but surveys in the community showed that these things constantly get done the wrong way.
The name of your add-on should mirror the functionality – don’t get too creative.
Have a nice icon (half the extensions don’t have an icon – even 40% of the approved ones – to battle this Mozilla is expanding the default “jigsaw icon” to more descriptive ones. They also offer a design help forum and run a icon redesign contest soon)
Provide helpful screenshots and keep them updated – video screenshots are in the planning
Avoid EULAs – Firefox now has different install buttons for EULA and non-EULA add-ons. Surveys showed that 44% of the plugins without a EULA got installed, but only 5% of those with a EULA. Another 40% of the installers dropped out after reading the EULA which means that only 3% got installed.
Listening to your audience
Justin’s last point was to listen to your users:
Have a good support avenue (email,website,get satisfaction)
Monitor user reviews – developer can reply to them
Use tools – statistics (how fast do people upgrade), recent activity feed as RSS, compatibility reporter
Myk Melez on Jetpack
Next up was Myk Melez with a deep dive on Jetpack. He started with a history and description of Jetpack which came from the Mozilla Labs. The reasons for Jetpack were that it was too hard to build add-ons, that browser updates broke add-ons, that restarting your browser is annoying and that add-ons have system access but probably don’t need it (which of course is a security issue aswell).
The goals of Jetpack subsequently are to simplify add-on development with CSS and JavaScript, to work with upgrades, to limit the power of plugins and to avoid restarts.
Jetpack came around in Spring 2009 and had these features but still allows for full system access. People liked it a lot, especially that you could build add-ons inside the browser which is great for casual developers.
There were however some issues with bootstrapping into Firefox and compatibility with updates and there was no way yet to harness third-party APIs in your extensions with Twitter being the most requested.
In Fall 2009 there was a reboot of Jetpack which included a web application for casual developers, an SDK for developers, XPI bundles + API bundled with add-in to solve bootstrapping and CommonJS Modules for code sharing with third parties.
In 2010 the webapp and SDK came out as a incubation programme of Mozilla instead of labs level and after five SDK releases, Jetpack is now restartless on 4 and betas, has a unit testing harness and documentation tool. The web app allows you to create add-ons and libraries and instant testing via a helper add-on.
Myk then did a live demo building a new extension using the of the add-Ons Builder (which is Bespin inside the browser allowing you to build extensions).
The future of Jetpack will have the limiting of system access, new APIs for window and sidebar, debugging options (console and memory management), compatibility across updates and the web app will get addons.mozilla.org integration.
After a quick break with awesome food and drinks (really) we headed for some lightning talks.
First up was Evgeny Shadchnev showing his Invisible hand price comparison Add-On. Specifically he explained how they moved from XPI development to Jetpack and how the test driven design allowed them simple development in a way no other browser extension platform does.
Next was Tobias Leingruber from Artzilla.org who talked about the lighter side of add-on development and hacking the web to be a funnier and more interesting place. I loved the talk as I myself have this mean streak for my add-ons (check Touretter as an example). Tobias talked about things artzilla had built, like a Dislike button for Facebook, the China channel firefox add-on that simulates the internet censorship in China and an add-on that finally removes Justin Bieber from the internet – thanks guys!.
Brian King talked about building add-ons for Firefox Mobile and pointed out the slow performance on handsets, the need for a different UI and how you can build cooler add-ons as you can tap into orientation, gps and camera. He also explained that you don’t need a phone to develop as there are nightly builds of desktop Fennec and a Maemo virtual image for Maemo apps (simulating a Nokia N900). One big tip was the Addon collector extension which allows for bunch syncing on extensions from desktop to mobile.
Paul Rouget and Tristan Nitot on Firefox 4 and HTML5
Paul and Tristan from the Paris office were next and blew our minds with some of the cool stuff coming up in Firefox 4
A reminder of what XUL is about
Paul started somewhat on a tangent by showing 3 tips for your first add-on. His main point was that you should understand XUL, CSS and JavaScript to build great add-ons (which somewhat contradicted the Jetpack talk but eh, he is French :) SCNR).
Paul explained that the Firefox UI is a big web page. Firefox itself is XUL and you can open it in Firefox itself with chrome://content/browser/browser.xul. He then showed how to build a browser in XUL using the XUL explorer in 20 lines of XML. Once you understood that the whole browser is a XUL document, the next step is to understand Overlay which means that you add to the browser’s chrome. You can find out where to inject your code using the DOM inspector.
All you need to do then is to write a manifest file and an install.rdf and package up your extension. All of this is described in detail at https://addons.mozilla.org/en-US/developers.
New features in Firefox
Firefox is getting a bad reputation right now for being slow and unstable. A lot of these issues are actually not the fault of the main engine but add-ons and – especially on a mac – plugins. Whenever my Firefox dies it is because of some Flash movie. This is why from 3.6.4 onwards Firefox will have a crash protection which means that if a Flash, Quicktime or Silverlight plugin crashes, the browser stays up and just tells you to reload the current page as
the plugin caused an issue.
Tristan re-iterated Mozilla’s cause and idea of the web as an open and free platform and that they are working hard to make it easy for developers to build with free tools what has been done with closed source platforms up to now.
Tristan and Paul then went through some Firefox 4 and Firefox Mobile 2 demos – some of which I had seen before, and others that impressed me a lot. Things Paul showed were:
HTML5 Video display
Painting with Canvas
Image manipulation with Canvas – pixel testing, face detection with opencivitas
Green screen technologies in images and video by detecting pixel colours.
APIs: Geolocation, Offline (IndexDB, localStorage, AppCache, FileAPI – binary content of a file input, file drag and drop, web workers, websockets)
Websockets controller running the presentation from the mobile.
WebGL
If you want to see some of the cool things they showed, here are some videos:
CSS3 filters and SVG masking on HTML5 Video:
Highly interactive video interface with SVG masking and transitions:
WebGL in Firefox 4 and on Android:
After this, Tristan covered some of the other features of Firefox 4, especially the upcoming speed improvements:
TraceMonkey (a new Javascript engine)
Lazy Frame Construction
Reducing I/O from the main thread
Startup Time
Hardware accelleration
GPU text/graphics/video rendering
Using GPU for text rendering
JavaScript JIT (JaegerMonkey)
HTML5 parser running own thread
slicker interface
no more modal dialogs
no startup interuptions
updates in the background
Other features of the upcoming interface are:
switch to tab (awesomebar storing open tabs)
dedicated application tabs (icon tab instead of text)
Permission control per web site – all the different options by domain
extensions as own page
The plan is to ship RC1 in October – let’s see if that works out :)
Summary
I had a great time at the event and I am convinced again that Mozilla are doing a great job in building the infrastructure for the Open Web. If you think only webkit is an HTML5 browser, check out some of this. One of my favourite parts of the whole demo at the end was that all of the examples are progressively enhanced, so if you watch them in a browser that is not Firefox you still get the features supported in that browser – something that the Apple showcase of HTML5 for example doesn’t bother to do.
I’ve been annoyed with the plethora of articles lately showing off HTML5 vs. Flash and building actually worse solutions using open technology. Therefore I thought I’ll have a go at it myself, too.
Instant rimshot is a fun site that has a button that plays a rimshot (the “babumm-tish” after a bad gag at a comedy club) when you press a large red button. I thought this is a good target to convert to CSS and HTML5 and I give you HTML5 instant rimshot.
There are not many HTML5 audio tutorials out there – if you Google for HTML5 audio you get video examples – and a lot of them not working.
HTML5 articles do not seem to get many fixes – the audio one above for example has a bug in the detection code (mentioned in the comments)
I had a hard time making the button work with the sound playing from start to end when you click the button. If you try the “version that loads the audio once and then calls the play() method onclick”:http://isithackday.com/html5-rimshot/rimshot.html you will find that the second time you hit the button it plays the “badumm” twice in Firefox – why I don’t know. Therefore I needed to create a new audio object every time you click the button – which in Safari means it keeps loading the MP3.
The necessary browser support forking and the repetition of the file in MP3 and OGG format is simply annoying – if there is a new technology we should demand from browser makers to bloody well do it right and not as a repetition of the late 90ies madness. I guess the latest announcement on I/O solves that issue – but Safari would still need a plugin to play.
The same applies to CSS gradients – progressively enhancing the button (on Firefox < 3.6 and on Opera it gets a plain colour) was another annoyance. Westciv’s gradient generator was a good helper for that.
Another interesting bug I found was that you cannot position things absolutely inside a BUTTON element in Firefox. Originally I had the button link as a button but gave up soon enough – see the example here.
All in all I love the idea of the open web and HTML5 leading the way into the future but I am seeing us wasting a lot of time trying to make things work cross-browser and if the final result for the end user is not much better then it will be hard to convince our bosses that the effort is worth the time and money.
What we need for that first and foremost are good examples and not “look what we can do” tutorials that neither use HTML5 nor CSS3 but jQuery to simulate the lot whilst we still call it “HTML5 solutions”.
Yesterday I had a back and forth on Twitter with Paul Irish and Divya Manian on Twitter about a thing that is full of win but also drives me crazy.
Those two lads built http://html5readiness.com/ – a beautiful demo of what you can do with CSS transformations, JavaScript and markup these days. Here’s what it looks like:
In essence this is the designer’s eye for http://caniuse.com/ which listed the same information in a lesser visual but very useful manner.
When I looked at the visualisation I went “WOW” and so did a lot of other people. But actually when using the site my fascination and interest quickly disolved.
I consider myself quite an observant person and I can read really, really fast. Looking at this visualization though I found myself constantly having to check from the coloured ray to the legend to understand just which browser we are currently talking about. Clicking the fixed browser position checkbox made this a bit more obvious but I am still very confused – especially as the colours are close to each other (on my laptop) and the rollover colour change doesn’t match the legend any more. This gets even more confusing when the colour of the main ray and the rollover changes:
I have no clue why the ray is coloured differently. I might think it is the connector between HTML5 and CSS3, but Geo Location is not part of HTML5.
The next thing I normally do to any interface is to turn off CSS to see how it degrades for non-visual users or on old mobile devices (yes, I do have to use an old Blackberry from time to time).
If you do this on HTML5 readiness you get a terrible experience:
There is no connection between the year names and the browser support (other than links – a nested list would make the connection much more obvious).
None of the links (like “Multiple backgrounds”) does anything.
What really made me very confused was looking at the source code though. The authors use B and I tags all over the shop and one of the rays for example is:
Back in the real world, however, WYSIWYG editors have B and I buttons which include these elements as BOLD and ITALIC. Now, as accessibility and semantics fans we’ve been bickering for years that this is a bad idea as this is painting with HTML rather than telling a user agent that the text needs to be emphasized or strong. We made quite some headway with this – and people started listening to us. Now we go back and say “oh well then, actually this is all fine – use whatever you want”.
All in all this example reminds me of something I built 8 years ago:
This was friggin cool back then. It was done for the Commodore 64 scene and it had to work in every browser that knows HTML - including Amiga ones. I managed to make it a “how is that done” moment by not using an image but instead a layout table with spacer gifs:
.: the very best of :.
Wow, terrible, right? Who would use tables for layout? This is madness – these are technologies we shouldn’t need to use any longer.
Or is it? By using the plethora of HTML elements in the visualisation above we do exactly the same thing! HTML is there to logically structure content and give it semantic meaning – not to paint lovely pictures.
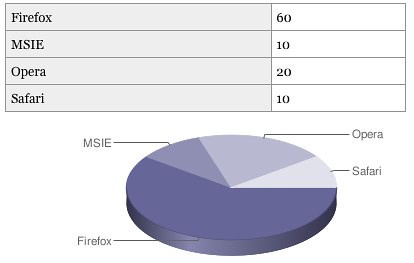
The page uses Can I use as its source of data – but instead of using a scraper and converting it to the necessary HTML (and by that making it possible to update automatically) the data is duplicated – and once displayed with no semantic value or logical structure whatsoever. We have the technology to convert sensible, good and clean HTML and turn it into something different. I’ve proven that in the past with the data table to charts conversion script:
I really don’t understand why we forget the simple promise we share with our users over and over again:
Build on stuff that works and then make it more interactive and pretty
In the case of this visualisation – use data tables and generate all the fluff and classes you need to make the CSS work out with JavaScript. Or – how about using SVG for the whole thing?
I am not saying that Paul and Divya did something bad – I am big fans of their work – I am just saying that we keep doing the same mistakes. If you would not write some HTML by hand and only need it for an effect – you are doing things wrong.
I am right now sitting at Heathrow Terminal 5 in London on my way outbound to a two week stint in the Silicon Valley (Sunnyvale/Mountain View) to meet with the US team. And here are the things that made me happy this morning:
Ian Pouncey continues to put together good thought-pieces on accessibility with Web Accessibility Myths.
Liz Danzico wrote a wonderful piece called confidence for good on how making a leap of faith in your career is sometimes very necessary.
UK House Prices, my entry to the data.gov.uk application showcase went down really well on the day of the release and got about 5000 hits on the first day. Now to pester the UK government to do more YQL and expect less SPARQL.
Constructing a POUR web site has some very solid advice on how to build a good web site. I am tired of people shoe-horning new acronyms though. POSH was a bad idea, so was HIJAX. Not because of what they stand for but for giving a way out. Hearing sentences like “yeah the solution is bad now, but we will go for a POSH one soon” or “this will be redesign with HIJAX in mind at a later stage” make me want to scream – an I heard both several times.













{kind=link}