Let’s solve the problem of loading external content (on other domains) with Ajax in jQuery. All the code you see here is available on GitHub and can be seen on this demo page so no need to copy and paste!
OK, Ajax with jQuery is very easy to do – like most solutions it is a few lines:
This will turn all elements with the class of ajaxtrigger into triggers to load “ajaxcontent.html” and display its contents in the element with the ID target.
This is terrible, as it most of the time means that people will use pointless links like “click me” with # as the href, but this is not the problem for today. I am working on a larger article with all the goodies about Ajax usability and accessibility.
However, to make this more re-usable we could do the following:
The issue I wanted to find a nice solution for is the one that happens when you click on the second link in the demo: loading external files fails as Ajax doesn’t allow for cross-domain loading of content. This means that see my portfolio will fail to load the Ajax content and fail silently at that. You can click the link until you are blue in the face but nothing happens. A dirty hack to avoid this is just allowing the browser to load the document if somebody really tries to load an external link.
If you look around the web you will find the solution in most of the cases to be PHP proxy scripts (or any other language). Something using cURL could be for example proxy.php:
It is also a spectacularly stupid idea to have a proxy script like that. The reason is that without filtering people can use this to load any document of your server and display it in the page (simply use firebug to rename the link to show anything on your server), they can use it to inject a mass-mailer script into your document or simply use this to redirect to any other web resource and make it look like your server was the one that sent it. It is spammer’s heaven.
Use a white-listing and filtering proxy!
So if you want to use a proxy, make sure to white-list the allowed URIs. Furthermore it is a good plan to get rid of everything but the body of the other HTML document. Another good idea is to filter out scripts. This prevents display glitches and scripts you don’t want executed on your site to get executed.
Something like this:
<?php$url=$_GET['url'];$allowedurls=array('http://developer.yahoo.com','http://icant.co.uk');if(in_array($url,$allowedurls)){$ch=curl_init();curl_setopt($ch, CURLOPT_URL,$url);curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);$output=curl_exec($ch);curl_close($ch);$content=preg_replace('/.*<body[^>]*>/msi','',$output);$content=preg_replace('/<\/body>.*/msi','',$content);$content=preg_replace('/<?\/body[^>]*>/msi','',$content);$content=preg_replace('/[\r|\n]+/msi','',$content);$content=preg_replace('/<--[\S\s]*?-->/msi','',$content);$content=preg_replace('/<noscript[^>]*>[\S\s]*?'.'<\/noscript>/msi','',$content);$content=preg_replace('/<script[^>]*>[\S\s]*?<\/script>/msi','',$content);$content=preg_replace('/<script.*\/>/msi','',$content);echo$content;}else{echo'Error: URL not allowed to load here.';}?>
But what if you have no server access or you want to stay in JavaScript? Not to worry – it can be done. YQL allows you to load any HTML document and get it back in JSON. As jQuery has a nice interface to load JSON, this can be used together to achieve what we want to.
Getting HTML from YQL is as easy as using:
select * from html where url="http://icant.co.uk"
select * from html where url="http://icant.co.uk"
YQL does a few things extra for us:
It loads the HTML document and sanitizes it
It runs the HTML document through HTML Tidy to remove things .NETnasty frameworks considered markup.
It caches the HTML for a while
It only returns the body content of the HTML - so no styling (other than inline styles) will get through.
As output formats you can choose XML or JSON. If you define a callback parameter for JSON you get JSON-P with all the HTML as a JavaScript Object – not fun to re-assemble:
foo({"query":{"count":"1","created":"2010-01-10T07:51:43Z","lang":"en-US","updated":"2010-01-10T07:51:43Z","uri":"http://query.yahoo[...whatever...]k%22","results":{"body":{"div":{"id":"doc2","div":[{"id":"hd","h1":"icant.co.uk - everything Christian Heilmann"},{"id":"bd","div":[{"div":[{"h2":"About this and me","
[... and so on...]
}}}}}}}});
foo({
"query":{
"count":"1",
"created":"2010-01-10T07:51:43Z",
"lang":"en-US",
"updated":"2010-01-10T07:51:43Z",
"uri":"http://query.yahoo[...whatever...]k%22",
"results":{
"body":{
"div":{
"id":"doc2",
"div":[{"id":"hd",
"h1":"icant.co.uk - everything Christian Heilmann"
},
{"id":"bd",
"div":[
{"div":[{"h2":"About this and me","
[... and so on...]
}}}}}}}});
When you define a callback with the XML output you get a function call with the HTML data as string in an Array – much easier:
foo({"query":{"count":"1","created":"2010-01-10T07:47:40Z","lang":"en-US","updated":"2010-01-10T07:47:40Z","uri":"http://query.y[...who cares...]%22"},"results":["<body>\n <div id=\"doc2\">\n<div id=\"hd\">\n
<h1>icant.co.uk - \n
everything Christian Heilmann<\/h1>\n
... and so on ..."]});
foo({
"query":{
"count":"1",
"created":"2010-01-10T07:47:40Z",
"lang":"en-US",
"updated":"2010-01-10T07:47:40Z",
"uri":"http://query.y[...who cares...]%22"},
"results":[
"<body>\n <div id=\"doc2\">\n<div id=\"hd\">\n
<h1>icant.co.uk - \n
everything Christian Heilmann<\/h1>\n
... and so on ..."
]
});
Using jQuery’s getJSON() method and accessing the YQL endpoint this is easy to implement:
$.getJSON("http://query.yahooapis.com/v1/public/yql?"+"q=select%20*%20from%20html%20where%20url%3D%22"+
encodeURIComponent(url)+"%22&format=xml'&callback=?",function(data){if(data.results[0]){var data = filterData(data.results[0]);
container.html(data);}else{var errormsg ='<p>Error: can't load the page.</p>';
container.html(errormsg);
}
}
);
$.getJSON("http://query.yahooapis.com/v1/public/yql?"+
"q=select%20*%20from%20html%20where%20url%3D%22"+
encodeURIComponent(url)+
"%22&format=xml'&callback=?",
function(data){
if(data.results[0]){
var data = filterData(data.results[0]);
container.html(data);
} else {
var errormsg = '<p>Error: can't load the page.</p>';
container.html(errormsg);
}
}
);
$(document).ready(function(){var container = $('#target');
$('.ajaxtrigger').click(function(){
doAjax($(this).attr('href'));returnfalse;});function doAjax(url){// if it is an external URIif(url.match('^http')){// call YQL
$.getJSON("http://query.yahooapis.com/v1/public/yql?"+"q=select%20*%20from%20html%20where%20url%3D%22"+
encodeURIComponent(url)+"%22&format=xml'&callback=?",// this function gets the data from the successful // JSON-P callfunction(data){// if there is data, filter it and render it outif(data.results[0]){var data = filterData(data.results[0]);
container.html(data);// otherwise tell the world that something went wrong}else{var errormsg ='<p>Error: can't load the page.</p>';
container.html(errormsg);
}
}
);
// if it is not an external URI, use Ajax load()
} else {
$('#target').load(url);
}
}
// filter out some nasties
function filterData(data){
data = data.replace(/<?\/body[^>]*>/g,'');
data = data.replace(/[\r|\n]+/g,'');
data = data.replace(/<--[\S\s]*?-->/g,'');
data = data.replace(/<noscript[^>]*>[\S\s]*?<\/noscript>/g,'');
data = data.replace(/<script[^>]*>[\S\s]*?<\/script>/g,'');
data = data.replace(/<script.*\/>/,'');
return data;
}
});
$(document).ready(function(){
var container = $('#target');
$('.ajaxtrigger').click(function(){
doAjax($(this).attr('href'));
return false;
});
function doAjax(url){
// if it is an external URI
if(url.match('^http')){
// call YQL
$.getJSON("http://query.yahooapis.com/v1/public/yql?"+
"q=select%20*%20from%20html%20where%20url%3D%22"+
encodeURIComponent(url)+
"%22&format=xml'&callback=?",
// this function gets the data from the successful
// JSON-P call
function(data){
// if there is data, filter it and render it out
if(data.results[0]){
var data = filterData(data.results[0]);
container.html(data);
// otherwise tell the world that something went wrong
} else {
var errormsg = '<p>Error: can't load the page.</p>';
container.html(errormsg);
}
}
);
// if it is not an external URI, use Ajax load()
} else {
$('#target').load(url);
}
}
// filter out some nasties
function filterData(data){
data = data.replace(/<?\/body[^>]*>/g,'');
data = data.replace(/[\r|\n]+/g,'');
data = data.replace(/<--[\S\s]*?-->/g,'');
data = data.replace(/<noscript[^>]*>[\S\s]*?<\/noscript>/g,'');
data = data.replace(/<script[^>]*>[\S\s]*?<\/script>/g,'');
data = data.replace(/<script.*\/>/,'');
return data;
}
});
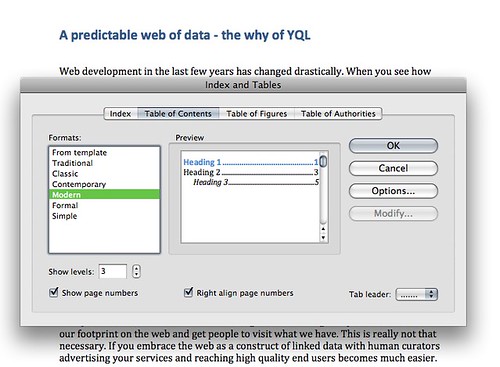
One thing I like about – let me rephrase that – one of the amazingly few things that I like about Microsoft Word is that you can generate a Table of Contents from a document. Word would go through the headings and create a nested TOC from them for you:
Now, I always like to do that for documents I write in HTML, too, but maintaining them by hand is a pain. I normally write my document outline first:
<h1id="cute">Cute things on the Interwebs</h1><h2id="rabbits">Rabbits</h2><h2id="puppies">Puppies</h2><h3id="labs">Labradors</h3><h3id="alsatians">Alsatians</h3><h3id="corgies">Corgies</h3><h3id="retrievers">Retrievers</h3><h2id="kittens">Kittens</h2><h2id="gerbils">Gerbils</h2><h2id="ducklings">Ducklings</h2>
<h1 id="cute">Cute things on the Interwebs</h1>
<h2 id="rabbits">Rabbits</h2>
<h2 id="puppies">Puppies</h2>
<h3 id="labs">Labradors</h3>
<h3 id="alsatians">Alsatians</h3>
<h3 id="corgies">Corgies</h3>
<h3 id="retrievers">Retrievers</h3>
<h2 id="kittens">Kittens</h2>
<h2 id="gerbils">Gerbils</h2>
<h2 id="ducklings">Ducklings</h2>
I then collect those, copy and paste them and use search and replace to turn all the hn to links and the IDs to fragment identifiers:
<li><ahref="#cute">Cute things on the Interwebs</a></li><li><ahref="#rabbits">Rabbits</a></li><li><ahref="#puppies">Puppies</a></li><li><ahref="#labs">Labradors</a></li><li><ahref="#alsatians">Alsatians</a></li><li><ahref="#corgies">Corgies</a></li><li><ahref="#retrievers">Retrievers</a></li><li><ahref="#kittens">Kittens</a></li><li><ahref="#gerbils">Gerbils</a></li><li><ahref="#ducklings">Ducklings</a></li><h1id="cute">Cute things on the Interwebs</h1><h2id="rabbits">Rabbits</h2><h2id="puppies">Puppies</h2><h3id="labs">Labradors</h3><h3id="alsatians">Alsatians</h3><h3id="corgies">Corgies</h3><h3id="retrievers">Retrievers</h3><h2id="kittens">Kittens</h2><h2id="gerbils">Gerbils</h2><h2id="ducklings">Ducklings</h2>
<li><a href="#cute">Cute things on the Interwebs</a></li>
<li><a href="#rabbits">Rabbits</a></li>
<li><a href="#puppies">Puppies</a></li>
<li><a href="#labs">Labradors</a></li>
<li><a href="#alsatians">Alsatians</a></li>
<li><a href="#corgies">Corgies</a></li>
<li><a href="#retrievers">Retrievers</a></li>
<li><a href="#kittens">Kittens</a></li>
<li><a href="#gerbils">Gerbils</a></li>
<li><a href="#ducklings">Ducklings</a></li>
<h1 id="cute">Cute things on the Interwebs</h1>
<h2 id="rabbits">Rabbits</h2>
<h2 id="puppies">Puppies</h2>
<h3 id="labs">Labradors</h3>
<h3 id="alsatians">Alsatians</h3>
<h3 id="corgies">Corgies</h3>
<h3 id="retrievers">Retrievers</h3>
<h2 id="kittens">Kittens</h2>
<h2 id="gerbils">Gerbils</h2>
<h2 id="ducklings">Ducklings</h2>
Then I need to look at the weight and order of the headings and add the nesting of the TOC list accordingly.
<ul><li><ahref="#cute">Cute things on the Interwebs</a><ul><li><ahref="#rabbits">Rabbits</a></li><li><ahref="#puppies">Puppies</a><ul><li><ahref="#labs">Labradors</a></li><li><ahref="#alsatians">Alsatians</a></li><li><ahref="#corgies">Corgies</a></li><li><ahref="#retrievers">Retrievers</a></li></ul></li><li><ahref="#kittens">Kittens</a></li><li><ahref="#gerbils">Gerbils</a></li><li><ahref="#ducklings">Ducklings</a></li></ul></li></ul><h1id="cute">Cute things on the Interwebs</h1><h2id="rabbits">Rabbits</h2><h2id="puppies">Puppies</h2><h3id="labs">Labradors</h3><h3id="alsatians">Alsatians</h3><h3id="corgies">Corgies</h3><h3id="retrievers">Retrievers</h3><h2id="kittens">Kittens</h2><h2id="gerbils">Gerbils</h2><h2id="ducklings">Ducklings</h2>
<ul>
<li><a href="#cute">Cute things on the Interwebs</a>
<ul>
<li><a href="#rabbits">Rabbits</a></li>
<li><a href="#puppies">Puppies</a>
<ul>
<li><a href="#labs">Labradors</a></li>
<li><a href="#alsatians">Alsatians</a></li>
<li><a href="#corgies">Corgies</a></li>
<li><a href="#retrievers">Retrievers</a></li>
</ul>
</li>
<li><a href="#kittens">Kittens</a></li>
<li><a href="#gerbils">Gerbils</a></li>
<li><a href="#ducklings">Ducklings</a></li>
</ul>
</li>
</ul>
<h1 id="cute">Cute things on the Interwebs</h1>
<h2 id="rabbits">Rabbits</h2>
<h2 id="puppies">Puppies</h2>
<h3 id="labs">Labradors</h3>
<h3 id="alsatians">Alsatians</h3>
<h3 id="corgies">Corgies</h3>
<h3 id="retrievers">Retrievers</h3>
<h2 id="kittens">Kittens</h2>
<h2 id="gerbils">Gerbils</h2>
<h2 id="ducklings">Ducklings</h2>
Now, wouldn’t it be nice to have that done automatically for me? The way to do that in JavaScript and DOM is actually a much trickier problem than it looks like at first sight (I always love to ask this as an interview question or in DOM scripting workshops).
Here are some of the issues to consider:
You can easily get elements with getElementsByTagName() but you can’t do a getElementsByTagName('h*') sadly enough.
You can do a getElementsByTagName() for each of the heading levels and then concatenate a collection of all of them. However, that does not give you their order in the source of the document.
To this end PPK wrote an infamous TOC script used on his site a long time ago using his getElementsByTagNames() function which works with things not every browser supports. Therefore it doesn’t quite do the job either. He also “cheats” at the assembly of the TOC list as he adds classes to indent them visually rather than really nesting lists.
It seems that the only way to achieve this for all the browsers using the DOM is painful: do a getElementsByTagName('*') and walk the whole DOM tree, comparing nodeName and getting the headings that way.
Another solution I thought of reads the innerHTML of the document body and then uses regular expressions to match the headings.
As you cannot assume that every heading has an ID we need to add one if needed.
So here are some solutions to that problem:
Using the DOM:
(function(){var headings =[];var herxp =/h\d/i;var count =0;var elms = document.getElementsByTagName('*');for(var i=0,j=elms.length;i<j;i++){var cur = elms[i];var id = cur.id;if(herxp.test(cur.nodeName)){if(cur.id===''){
id ='head'+count;
cur.id= id;
count++;}
headings.push(cur);}}var out ='<ul>';for(i=0,j=headings.length;i<j;i++){var weight = headings[i].nodeName.substr(1,1);if(weight > oldweight){
out +='<ul>';}
out +='<li><a href="#'+headings[i].id+'">'+
headings[i].innerHTML+'</a>';if(headings[i+1]){var nextweight = headings[i+1].nodeName.substr(1,1);if(weight > nextweight){
out+='</li></ul></li>';}if(weight == nextweight){
out+='</li>';}}var oldweight = weight;}
out +='</li></ul>';
document.getElementById('toc').innerHTML= out;})();
(function(){
var headings = [];
var herxp = /h\d/i;
var count = 0;
var elms = document.getElementsByTagName('*');
for(var i=0,j=elms.length;i<j;i++){
var cur = elms[i];
var id = cur.id;
if(herxp.test(cur.nodeName)){
if(cur.id===''){
id = 'head'+count;
cur.id = id;
count++;
}
headings.push(cur);
}
}
var out = '<ul>';
for(i=0,j=headings.length;i<j;i++){
var weight = headings[i].nodeName.substr(1,1);
if(weight > oldweight){
out += '<ul>';
}
out += '<li><a href="#'+headings[i].id+'">'+
headings[i].innerHTML+'</a>';
if(headings[i+1]){
var nextweight = headings[i+1].nodeName.substr(1,1);
if(weight > nextweight){
out+='</li></ul></li>';
}
if(weight == nextweight){
out+='</li>';
}
}
var oldweight = weight;
}
out += '</li></ul>';
document.getElementById('toc').innerHTML = out;
})();
To work around the need to traverse the whole DOM, I thought it might be a good idea to use regular expressions on the innerHTML of the DOM and write it back once I added the IDs and assembled the TOC:
(function(){var bd = document.body,
x = bd.innerHTML,
headings = x.match(/<h\d[^>]*>[\S\s]*?<\/h\d>$/mg),
r1 =/>/,
r2 =/<(\/)?h(\d)/g,
toc = document.createElement('div'),
out ='<ul>',
i =0,
j = headings.length,
cur ='',
weight =0,
nextweight =0,
oldweight =2,
container = bd;for(i=0;i<j;i++){if(headings[i].indexOf('id=')==-1){
cur = headings[i].replace(r1,' id="h'+i+'">');
x = x.replace(headings[i],cur);}else{
cur = headings[i];}
weight = cur.substr(2,1);if(i<j-1){
nextweight = headings[i+1].substr(2,1);}var a = cur.replace(r2,'<$1a');
a = a.replace('id="','href="#');if(weight>oldweight){ out+='<ul>';}
out+='<li>'+a;if(nextweight<weight){ out+='</li></ul></li>';}if(nextweight==weight){ out+='</li>';}
oldweight = weight;}
bd.innerHTML= x;
toc.innerHTML= out +'</li></ul>';
container = document.getElementById('toc')|| bd;
container.appendChild(toc);})();
(function(){
var bd = document.body,
x = bd.innerHTML,
headings = x.match(/<h\d[^>]*>[\S\s]*?<\/h\d>$/mg),
r1 = />/,
r2 = /<(\/)?h(\d)/g,
toc = document.createElement('div'),
out = '<ul>',
i = 0,
j = headings.length,
cur = '',
weight = 0,
nextweight = 0,
oldweight = 2,
container = bd;
for(i=0;i<j;i++){
if(headings[i].indexOf('id=')==-1){
cur = headings[i].replace(r1,' id="h'+i+'">');
x = x.replace(headings[i],cur);
} else {
cur = headings[i];
}
weight = cur.substr(2,1);
if(i<j-1){
nextweight = headings[i+1].substr(2,1);
}
var a = cur.replace(r2,'<$1a');
a = a.replace('id="','href="#');
if(weight>oldweight){ out+='<ul>'; }
out+='<li>'+a;
if(nextweight<weight){ out+='</li></ul></li>'; }
if(nextweight==weight){ out+='</li>'; }
oldweight = weight;
}
bd.innerHTML = x;
toc.innerHTML = out +'</li></ul>';
container = document.getElementById('toc') || bd;
container.appendChild(toc);
})();
You can see the regular expressions solution in action here. The problem with it is that reading innerHTML and then writing it out might be expensive (this needs testing) and if you have event handling attached to elements it might leak memory as my colleage Matt Jones pointed out (again, this needs testing). Ara Pehlivavian also mentioned that a mix of both approaches might be better – match the headings but don’t write back the innerHTML – instead use DOM to add the IDs.
Libraries to the rescue – a YUI3 example
Talking to another colleague – Dav Glass – about the TOC problem he pointed out that the YUI3 selector engine happily takes a list of elements and returns them in the right order. This makes things very easy:
There is probably a cleaner way to assemble the TOC list.
Performance considerations
There is more to life than simply increasing its speed. – Gandhi
Some of the code above can be very slow. That said, whenever we talk about performance and JavaScript, it is important to consider the context of the implementation: a table of contents script would normally be used on a text-heavy, but simple, document. There is no point in measuring and judging these scripts running them over gmail or the Yahoo homepage. That said, faster and less memory consuming is always better, but I am always a bit sceptic about performance tests that consider edge cases rather than the one the solution was meant to be applied to.
Moving server side.
The other thing I am getting more and more sceptic about are client side solutions for things that actually also make sense on the server. Therefore I thought I could use the regular expressions approach above and move it server side.
The server side solutions have a few benefits: they always work, and you can also cache the result if needed for a while. I am sure the PHP can be sped up, though.
All of these solutions are pretty much rough and ready. What do you think how they can be improved? How about doing a version for different libraries? Go ahead, fork the project on GitHub and show me what you can do.
I am currently in (freezing) Oslo in Norway and about to leave for the NITH university for the Yahoo and Opera developer evening. Here are the slides and notes of what I am about to present tonight. Audio will follow laterAudio is now available.
For those who will attend tonight: stop right here, you’ll just spoil it for yourself :)
Things you can use (by the Yahoo Developer Network and friends)
In the following hour or so I will be talking to you about some of the things that have been done for you that you can build on. Web development is confusing enough as it is. There is no need to make it more complex by not using what has been done for us already. But first, a few facts about me:
I am Chris and I’ve been developing web sites for about 12 years. I’ve worked with numerous frameworks and CMS and I’ve delivered various international and high-traffic sites. I’ve written several books and dozens of articles and hundreds of blog posts on the subject of web development, accessibility, performance, maintainability, internationalization and many other things I had to battle in my day to day job.
I work for the Yahoo Developer Network and you will find most of the things I will talk about today there.
Learning the basics
The good thing about these days we live in is that we have great resources on the web to learn good basics of web development. That we still learn it by viewing source and trial and error after copy and paste is human nature but also keeps us from evolving. The Opera Web Standards curriculum is an amazing resource to learn web standards based development (as is the WaSP interact) and the Yahoo Developer Network theatre is full of videos of talks and tutorials. All of this is free to use and to build upon.
Starting with a clean canvas
One thing I learnt is that in order to deliver products that work and are fun to maintain you need to work on a solid base. Web development is hindered by the fact that our deployment environment is totally unknown to us. This is why we need to even the playing field before we should go out on the pitch to play.
You achieve this by defining what you call “support” for browsers. In the case of Yahoo this is the graded browser support document. If you aim to make your web product look and work the same on every browser out there you are doing it wrong. Web design is meant to go with the flow and accustom itself to the ability of the user agent (browser in most cases). At Yahoo, we have the Graded Browser Support for this – browsers that are not capable of supporting new technologies will not get them. Web sites are not meant to look and work the same everywhere. On the contrary – the ability to accustom the interface to different user agents is what makes web development so powerful.
CSS frameworks and frontend libraries
The next step is to free ourselves from the limitations of browsers and especially their differences. This is what CSS frameworks and front end libraries like jQuery, Mootools, Dojo, YUI and many more are for. All of these have the same goal: allow you to build code that is predictable and limited to the bare necessities. We should not have to bloat our code just to make our products work with random browser implementation problems. These are a moving target as there is all kind of weirdness happening across the board. Libraries make our job predictable and allow us to use web standards without catering for browsers. If you build your code based on libraries you can fix your product for the next browser by upgrading the library. If you choose to do everything yourself – good luck.
Building interfaces that work
The next thing to consider is that an application interface is not just the look and feel. In order to make it work for everybody we’ll need to understand the ways users interact with our products. This includes simple usability (not overloading the user, not confusing the user) but also means knowing about different interaction channels – for example keyboard users. A great resource for starting the journey towards usable interfaces is the Yahoo Design pattern library. There we collected information how our end users use the web and reach a goal easily. If anything, have a look at these patterns before you start building your first widget or application. They even come with stencils for different designer tools.
Using the web
The big change in web development over the last few years was that we stopped trying to do everything ourselves. The web is full of specialized systems such as YouTube, Flickr and Google Maps that allow you to host data in specific formats and make it dead easy for you to convert and re-use that data in web formats. Using this information happens via Application Programming Interfaces or short APIs. These allow you to demand data in a certain format and get back only what you need. There are hundreds of APIs available on the web. For an idea of what is available, check out programmableweb.com.
Thinking data first
The main thing to be aware of if you want to build great products is to separate your data from your presentation. This is essential to allow for localization, internationalization and to keep your code maintainable. In the case of a mashup of different data sources this means you need to think about making it as easy as possible for you to use different APIs. The complexity of your product increases with the number of APIs you use. Every API has different ways to authenticate, expects different parameters and returns data in different formats.
Mixing the web with YQL
YQL is a solution that Yahoo built for its own needs. All of our products are built on APIs – for scalability reasons. Having to learn all these APIs and negotiating access cost us a lot of our time so we thought we’d come up with a better solution. This solution is called YQL. YQL is a SQL-style language to get data from the web. The following query would get us photos of London from flickr:
select * from geo.places where text="london"
Or would it? Actually it would give us photos with the text “london” and not photos taken in Oslo. If we wanted that we need to use another API. The Yahoo Geo APIs allow you to define any place on earth and get it back as a “where on earth ID” or short woeid. This format is supported by flickr, so we can use these APIs together. Twitter will also soon support this.
select * from flickr.photos.search where woe_id in (
select woeid from geo.places
where text="london"
)
This gives you some data of the photos you want to show but not all, so let’s use another API method to get that information.
select * from flickr.photos.info where photo_id in(
select id from flickr.photos.search where woe_id in(
select woeid from geo.places where text="london"
)
)
This is a lot of data so in order to only retrieve what we really need we can filter the data down by replacing the *:
select farm,id,secret,owner.realname,
server,title,urls.url.content
from flickr.photos.info where photo_id in(
select id from flickr.photos.search where woe_id in(
select woeid from geo.places where text="london"
)
)
Using this query in the YQL console, choosing YQL as the output format and “flickr” as the callback will give us a valid URL to use in a browser or script:
Using this in the src attribute of a script tag and writing a few lines of Dom Scripting displays the photos.
Is this limited to Yahoo?
No, of course not. First of all you can use any data on the web as a source using the atom, csv, feed, html, json, microformats, rss and xml tables.
Scraping HTML with YQL
The HTML table is quite interesting as it allows you to get data from any HTML document, cleans it up by running it through HTML Tidy and then allows you to access parts of it using XPATH.
You can also add your own data by providing a simple XML schema called an open table. In this schema you need to tell YQL what the data endpoint is, what parameters are expected and what gets returned.
Open tables also allow for an execute block which allows you to write JavaScript that will be executed by YQL on the server side using Rhino and has full e4x support.
The best thing you can do right now if you want to build a web application is using already tested and working building blocks. The Yahoo User Interface library is full of these as this is exactly how we build our own tools.
For creating layouts with CSS without having to know all the hacks that browsers need you can use the YUI grids and if you are really lazy you can even use the WYSIWYG grids builder.
Using the CSS grids and some of the YUI widgets it is very easy to build a working application that is tested across all the browsers defined in the graded browser support. Examples are this geographical Flickr search and a showcase to get information for Delhi.
One thing that is really useful about the widgets provided in YUI is that they are all driven by custom events. That way you can extend and change their functionality without having to mess around with the code. Simply write an event listener for the custom event, add your functionality and prevent the original functionality.
Another great benefit of YUI is the very detailed documentation and the hundreds of examples you can use to get you started.
Wanna get super famous?
The last thing I want to talk about today is the Yahoo Application Platform or short YAP. Using YAP you can build a web application using JavaScript, HTML and CSS and add it to the Yahoo Homepage, My Yahoo and in the future even more properties of Yahoo.
You start at and develop your application to the largest part in your Applications Dashboard. Yahoo apps have two views: a small view which is more or less static (but allows for some Ajax) and a large view which gives you full access and much wider screen space. The small view is overlayed over the Yahoo page and will show Yahoo ads next to it. The large view can be monetized by you.
One thing that can be a bit of a frustration about YAP when you go at it with a normal web development mindset is that not all CSS/HTML and JavaScript is allowed as YAP uses Caja to keep our applications secure. Therefore we’ve put together some Caja-ready code examples to get you on track.
The easiest way to build YAP apps is by using the Yahoo Markup Language (YML) and YUI as YUI was re-written to be Caja compliant.
If you want to take a look at what a YAP application looks like, check out the source of TweetTrans on GitHub. In essence it is a simple PHP API call using YQL and a YML interface to display the results using Ajax. No JavaScript involved as YML does that for us.
You can install TweetTrans by clicking the following link: http://yahoo.com/add?yapid=zKMBH94k. This is also the way to promote your own applications (simply replace the application ID with yours) until the YAP application gallery is up and running.
The more powerful way of promoting your application in Yahoo is to piggy-back on our social connections and you can do this by diving into the social graph API. The easiest way to do that is to use the social SDK also available on GitHub. Notice that the SDK will not work on a localhost – you need to run it inside the application dashboard or a Yahoo container on the homepage.
Elevator pitches
Yahoo User Interface Library – YUI
YUI is the system that Yahoo uses to build its web sites. It is constantly tested to work for the largest amount of users, free, open source and covers everything from design patterns to out-of-the-box widgets. It is modular and you can use only what you need. You can either host it yourself or get it from a network of distributed servers.
Yahoo Query Language – YQL
YQL is a web service that allows you to mash-up any data on the web from various sources with a simple SQL-style language. You can filter the data down to what you need and you can convert the data with server-side JavaScript before returning it. Data providers can use YQL to publish an API on the web on top of Yahoo’s infrastructure and cloud storage.
Yahoo Application Platform – YAP
YAP is the Yahoo Application Platform which allows you to build applications that run on the Yahoo homepage and soon other properties. You can dive into Yahoo’s social graph to promote your applications and you can create highly secure web apps as YAP uses Caja to ensure code quality.
Here are the slides, the audio recording and my notes for the keynote of the full frontal conference held yesterday in Brighton, England. It was a blast, thank you Remy and Julie!
The following was the description of the talk introducing the ideas to the attendees of full frontal.
Frontloaded and zipped up – do loose types sink ships?
JavaScript had a bumpy ride up to now, from its origins as a CGI-replacement, initiator of countless popups and annoying effects over the renaissance as Ajax enabler up to becoming wrapped up in libraries to work around the hell that is browser differences. With the ubiquity of JavaScript comes a new challenge. How do we keep JavaScript safe when browsers don’t really distinguish between different sources and give them all the same rights? Why do we still judge the usefulness of JavaScript by how badly browsers speak it? Learn about some environments you can use JavaScript in securely and marvel at the magic and annoyances that are technologies that try to put a lock on the issue of JavaScript security.
A quick trip down memory lane.
When I first encountered JavaScript it was mainly used to do simple calculators, window manipulation and simple form validation. The main interface used was the browser object model with window being the main object and form and element being the collections to manipulate. You added content either by changing the value of a form field or by using document.write() with the latter being different from browser to browser. The other thing you had was the images array and this is what we used extensively to create rollovers.
Event handling was done with on{event} inline handlers and the body always had an onload handler on it.
Bring on the bling!
That however did not stop us from already abusing JavaScript to create pointless bells and whistles. Status bar tickers, title changing scripts and moving popup windows were the first to annoy the end user and they were just the start.
More bling.
With browsers starting to allow you to manipulate more of the document (via document.all and document.layers) and new and bespoke CSS extensions we had even more options to do very annoying and pointless things. Animated menus, rainbow cycling scrollbars, the floating (and flickering) Geocities logo, mousetrails and other abominations were built to bling up our sites and subsequently the audience got sick of JavaScript and discarded it as a toy.
Ajax for the win!
This all changed when Ajax came around and there was no way not to have some way or another you load content on demand using XMLhttpRequest – if you wanted to have a cool web site that is. And of course people used it wrongly.
Security scares.
As people used JavaScript to load information that should not be visible to the world and it is easy to intercept and see everything that happens in a browser in JavaScript we have more and more security scares coming up.
Is JavaScript a security problem?
This bears the question if JavaScript in itself is a security problem and if we should discard it at all.
Security flaws start at the backend but JavaScript gets the blame.
Last week I came across an interesting survey by the security company Cenzic – get the PDF here. They looked at the state of the web and the main security problems in the first two quarters of 2009. The survey showed that the browser was responsible for only 8% of the overall security issues.
One thing that is interesting is that most security flaws start with a problem on the backend but get blamed on JavaScript. XSS is a backend problem, but it becomes a problem as JavaScript is designed to give scripts too many rights.
JavaScript implementation vs. JavaScript
The problem is not JavaScript itself – well, not exclusively – it is mostly the implementation of it in browsers. And funnily enough this is how we measure the quality of the language. It is like judging the quality of a book by its movie.
Browsers don’t care where JavaScript comes from.
To a browser, every JavaScript has the same rights to the content of the page and other things JavaScript can reach – and that includes cookies. When I can steal your cookies I can steal your users’ identities and this is a big security issue.
Browsers are full of security holes.
The other issue is that browsers are full of security faults. This can be interesting as people complain about IE6 and its flaws, but the survey actually ranked Firefox and Safari as the most vulnerable browsers. The reasons are plugins in the case of Firefox and – in Safari’s case – the iPhone. Interesting targets are always successful platforms.
Plugins have and still are a main source for security issues. Especially in the case of IE Flash and PDF display was always a problem. The reason is simple – plugins extend the reach of the browser into the file system and that is an interesting attack vector. So if you offer PDF documents and you want to keep your system secure it might be a good idea to loop them through a script that sets a header that forces user download – this also allows you to add statistics to the PDF downloads.
So we can’t use JavaScript, right?
Which brings a lot of people not to trust JavaScript at all and see it as the source of all evil. Plugins like NoScript are all the rage and the security-conscious are happy to call JavaScript the source of all evil.
It is about spreading the joy of JavaScript.
JavaScript is an amazingly useful part of the interfaces we give our end users. Totally turning it off or not using it means we give up on a lot of things that our users should get and expect from an interface in 2009. I like that I can write a message while an attachment uploads in the background.
Learning JavaScript
The first thing to remember is that this is not 1997. We don’t have to learn JavaScript by looking at other people’s source code. Opera’s web standards curriculum and The Yahoo video theatre are great resources to take your first steps into the JavaScript world.
What to use JavaScript for
The main thing is to remember what we should use JavaScript for:
warning users about flawed entries (password strength for example)
extending the interface options of HTML to become an application language (sliders, maps, comboboxes…)
Any visual effect that cannot be done safely with CSS (animation, menus…)
CSS has come a long way but unless you can control the animation and be sure it works cross-browser it is not a replacement. Menu systems using CSS only are a gimmick as they cannot be made keyboard accessible.
What not to use JavaScript for
Sensitive information (credit card numbers, any real user data)
Cookie handling containing session data
Trying to protect content (right-click scripts, email obfuscation)
Replacing your server / saving on server traffic without a fallback
What if you need more?
All this becomes an issue when you get into developing large web products where you push the envelope of what can be done with the web and the technologies right now. The new Yahoo homepage is one of these examples – in it we wanted to allow third party developers to build own applications and run them safely inside ours without endangering the privacy of our users.
You can limit yourself
One thing you can do is to limit yourself to the “safe” parts of a language. Douglas Crockford’s AdSafe takes this approach and is meant as a guideline for ad providers.
You can pre-process JavaScript
The other option is to enforce the limitation of the language by pre-processing JavaScript and converting it to a safer subset. The main tool for this nowadays is Caja which has been invented by Google and now made workable by Google and Yahoo for the Open Social platform. Caja converts JavaScript to a safe subset – either on the client or on the server.
Things Caja doesn’t allow you to do
To ensure the security of our applications, Caja stops you from using some things you might have gotten accustomed to using in the last few years.
Caja and HTML
Here are the things you cannot use in HTML:
name attributes
custom attributes
custom tags
unclosed tags
embed
iframe
link rel=”...”
javascript:void(0)
radio buttons in IE
relative URLs
Caja and JavaScript
Things you need to keep out of your JavaScript:
eval()
new Function()
strings as event handlers (node.onclick = ‘...’;)
names ending with double / triple underscores
with function (with (obj) { ... })
implicit global variables (specify var variable)
calling a method as a function
document.write
window.event
ajax requests returning JS
Caja and CSS
And last but not least things deemed dangerous in CSS are:
star hacks
underscore hacks
IE conditionals
Insert-after clear fix
expression()
*@import
Caja ready code examples
You can find a good collection of Caja ready code examples in the Yahoo Application Platform documentation.
Caja problems and making it easier
Whilst Caja is a great idea to ensure the security of widgets it is not without its problems. If you chose client-side conversion it means a massive dent in the performance of your application and even with server-side conversion it becomes harder to build new systems. For starters, Caja-converted code is very hard to read and therefore debug and in many cases it means that as a developer you need to change your ways.
Libraries and Caja compliance
Much like we fix browsers, we can also use libraries to make our Caja-compliant development easier. The first library to be fully Caja compliant is the Yahoo User Interface library and other libraries like jQuery have also shown interest in compliance.
Abstracting the issue with an own language – YML
The other way to make it easier to write secure code is to abstract most of th changes to our normal development ways out into an own markup language. Facebook had done this and in Yahoo’s case there is the Yahoo Markup language or short YML. Using this language in a widget for the Yahoo homepage you can do Ajax requests and dig into the Yahoo social graph without having to write any JavaScript or server-side code.
Extending browsers
Another interesting way to make JavaScript development more interesting is to think about browser extensions. This starts with GreaseMonkey which allows Firefox users to extend any web site out there with new functionality using a few lines of Dom Scripting – a great way for example to do quick prototyping. Google Gears, Yahoo Browser Plus and and Mozilla Jetpack kick this idea up a notch and give you new APIs to extend the reach of the browser into local storage, allow for database access in JavaScript and give you worker threads to do heavy computations without slowing down the main interface. These extensions give browsers the power we would love to have to be able to deliver real applications inside browsers.
Moving out of the browser
The other thing you can do with JavaScript these days is to move outside the browser and take your HTML, CSS and JavaScript solutions to other platforms.
Widget frameworks
Widget frameworks have been around for a while with Konfabulator and Apple Dashboard widgets leading the way. Opera also allows you to run small applications outside the confines of a browser window. The interesting thing about widgets is that they always looked much prettier than most web solutions – mainly because PNG support was a given and not something you had to hack for MSIE.
W3C widgets
W3C widgets are a standard that allows you to zip up an HTML document with CSS, JavaScript and images and run it as a self-contained widget. Peter-Paul Koch has written a great introduction to W3C widgets and several mobile phone providers (first and foremost Vodafone) offer a way to run these widgets on handsets without the need to learn any mobile OS language or tools.
Adobe Air
Adobe Air has made it possible for web developers to write full-blown installable applications that run across several operating systems and have access to databases and the file system. Probably the most successful apps are Twitter clients and music apps like Spotify.
Command line JavaScript – Rhino
If you don’t like all the fancy visual stuff and you want to use JavaScript to do some heavy data conversion you can use JavaScript on the command line using Rhino which is a Java implementation of JavaScript. The really cool thing about writing JavaScript for the command line is that it supports all the features of the language and you are not at the mercy of a browser to do it right.
Turning JavaScript Mashups into web services.
One rather new opportunity for developers is that you can use YQL or Yahoo Query Language to easily mash-up and filter data from several data sources on the web. YQL allows you to:
mashup data with a SQL-style syntax
filter down to the absolutely necessary data
return as XML, JSON, JSON-P and JSON-P-X
use Yahoo as a high-speed proxy to retrieve data from various sources.
use Yahoo as a rate limiting and caching proxy when providing data.
Retrieving data from an HTML document and choosing the right output format
Using YQL it is dead easy for example to retrieve the headlines from an HTML document with the following statement.
select * from html where url="http://2009.fullfrontal.org" and xpath="//h3"
YQL is a web service in itself and you can retrieve the data returned from this request in different formats.
XML returns the data as an XML file which is not that useful in a JavaScript environment.
JSON is natively supported and therefore much easier to parse.
JSON-P wraps the returned JSON object in a JavaScript function call and thereby makes it very easy to use in a script node (either hardcoded or created on the fly).
JSON-P-X wraps the returned JSON object in a JavaScript function call and returns the XML content (in this case the scraped HTML) as a string. This makes it very easy to use innerHTML to render the data in a browser without having to loop through the JSON object and re-assemble the string.
Retrieving photos for a certain geographical location
As a demo, try this out. In order to retrieve photos for a certain geographical location you can use the geo and Flickr APIs in a single YQL statement:
select farm,id,secret,owner.realname,server,title,urls.url.content
from flickr.photos.info where photo_id in(
select id from flickr.photos.search where woe_id in(
select woeid from geo.places where text="london"
)
)
Moving JavaScript solutions into YQL to turn them into web services
The problem with the solution above is that you make yourself dependent on JavaScript to show these photos. If you want to still use JavaScript but allow users without it to see these photos you can use a YQL open table with embedded JavaScript to do the conversion. YQL uses Rhino to run and execute your JavaScript server-side and returns you the content you created inside an XML or JSON file. As JavaScript is executed on the server, you have full E4X support to make the use of XML painless and you can use advanced JavaScript like for each:
var amt = amount || 10;
var query = 'select farm,id,secret,owner.realname,server,title,'+
'urls.url.content from flickr.photos.info where '+
'photo_id in (select id from flickr.photos.search('+
amount + ') where ';
if(location!==null){
query += 'woe_id in (select woeid from geo.places where text="' +
location+'") and ';
}
query += ' text="' + text + '" and license=4)'
var x = y.query(query);
var out =
;
for each(var cur in x.results.photo){
var li = ;
var a = ;
a.@["href"] = cur.urls.url;
var img = ;
var url = 'http://farm' + cur.@farm + '.static.flickr.com/' +
cur.@server + '/'+cur.@id + '_' + cur.@secret +
'_s.jpg';
img.@["src"] = url;
img.@["alt"] = cur.title;
a.img = img;
li.a = a;
out.li += li;
}
response.object = out;
This, embedded in an open table means you can retrieve photos from Flickr as a UL now using the following YQL statement:
select * from flickr.photolist where text="me" and location="uk" and amount=20
Or with a very simple JavaScript, thanks to the JSON-P-X output format:
Another example – scraping HTML from web pages that need POST data
Another powerful example of what you can do with JavaScript when you embed it into a YQL table is the following:
Christian HeilmannHTML pages that need post datahttp://www.wait-till-i.com/2009/11/16/using-yql-to-read-html-from-a-document-that-requires-post-data/
As explained in detail in this blog post this JavaScript extends the HTML scraping option of YQL to allow for POST data to be sent to a document before retrieving the HTML:
select * from htmlpost where
url='http://isithackday.com/hacks/htmlpost/index.php'
and postdata="foo=foo&bar=bar" and xpath="//p"
Notice that YQL execute gives you full REST and HTTP support and has the xpath conversion built-in as a on own function.
oAuth in JavaScript – the netflix example
Another interesting example is the open table provided by Netflix, which shows you how you can use oAuth in JavaScript:
// Include the OAuth libraries from oauth.net
y.include("http://oauth.googlecode.com/svn/code/javascript/oauth.js");
y.include("http://oauth.googlecode.com/svn/code/javascript/sha1.js");
// Collect all the parameters
var encodedurl = request.url;
var accessor = { consumerSecret: cks, tokenSecret: ""};
var message = { action: encodedurl, method: "GET", parameters: [["oauth_consumer_key",ck],["oauth_version","1.0"]]};
OAuth.setTimestampAndNonce(message);
// Sign the request
OAuth.SignatureMethod.sign(message, accessor);
try {
// get the content from service along with the OAuth header, and return the result back out
response.object = request.contentType('application/xml').header("Authorization", OAuth.getAuthorizationHeader("netflix.com", message.parameters)).get().response;
} catch(err) {
response.object = {'result':'failure', 'error': err};
}
Liberating our JavaScript
As you can see switching environments liberates our JavaScript solutions and gives us much tighter security. So open your minds and don’t judge JavaScript by its implementation. Instead have fun with it and use it wisely. With great power comes great responsibility.