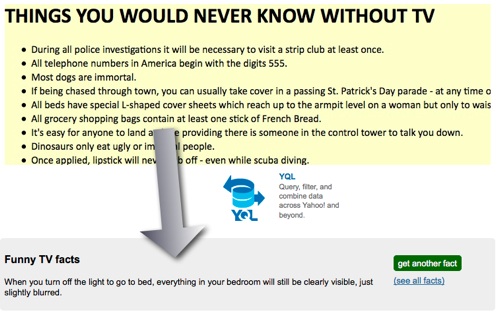
During the Summer of Widgets hack event last weekend, Tomas Caspers, Nina Wieland and Jens Grochdreis had the idea of creating a translation tool to translate from the local Cologne accent to German and back.
For this, they found a pretty impressive data source on the web, namely this web site by Reinhard Kaaden. The task was now to turn this into a fancy interface to make it easy for people to enter a “Kölsch” term and get the German equivalent and vice versa. For this, I proposed YQL und YUI and here is a step-by-step explanation of how you can do it.
You can see the final outcome here: Deutsch-Kölsch übersetzer
or by clicking the screenshot:
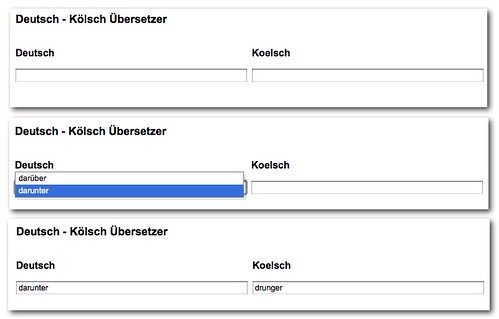
Step 1: Retrieve and convert the data
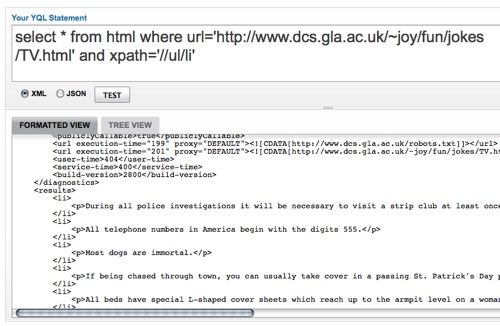
A very easy way to get data from the web is using YQL. In order to get the whole HTML of the source page all we had to do is select * from html where url='http://www.magicvillage.de/~reinhard_kaaden/d-k.html'. That gave us the whole data though and we only wanted to get the content of the tables.
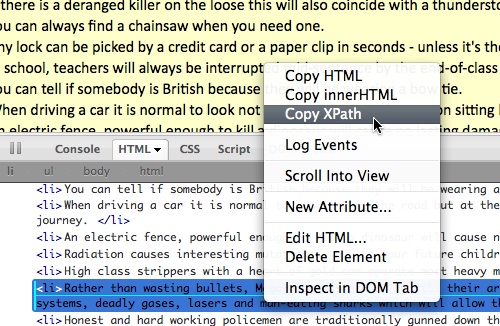
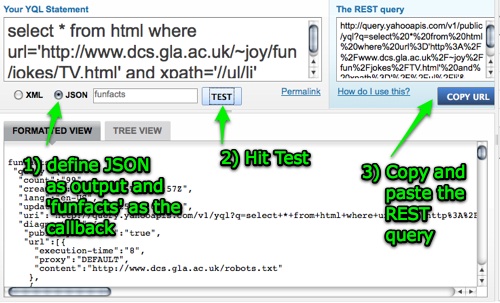
Using Firebug and looking up some XPATH we came up with the following statement that would give us the language pairs as German-Koelsch inside paragraphs: //table[1]/tr/td/p[not(a)]. The not(a) statement is needed to filter out the A-Z navigation table cells. We chose JSON as the output format in YQL and dktrans as the callback function name.
All in all this gave us a URL that would load the data we wanted and send it to the function dktrans once it has been pulled:
All that had to go in there to create the Autocomplete controls was more or less 100% copied from the simple Autocomplete example on the YUI site.
First thing is to get some handlers to the input fields I want to populate with the translation data:
var di = YAHOO.util.Dom.get('deutschinput');
var ci = YAHOO.util.Dom.get('koelschinput');
Then you need to instantiate the data source for the autocomplete and give it the language array. As a responseSchema you can define a field called term:
dktransdata.cologneDS = new YAHOO.util.LocalDataSource(
dktransdata.koelsch
);
dktransdata.cologneDS.responseSchema = {fields:['term']};
Next you need to instantiate the AutoComplete widget. This one gets three parameters: the input element, the output container and the data source. You can set useShadow to get a small dropshadow on the container:
dktransdata.cologneAC = new YAHOO.widget.AutoComplete(
'koelschinput','koelschoutput',dktransdata.cologneDS
);
dktransdata.cologneAC.useShadow = true;
This turns the input of the Cologne language into an Autocomplete, but it doesn’t yet populate the other field. For this we need to subscribe to the itemSelectEvent of the AutoComplete widget. The event handler of that event gets a few parameters, the text content of the chosen element is the first element of the third element in the second parameter (this is explained in detail on the YUI site). All you need to do is set the value of the other field to the corresponding element of the translation maps we defined:
dktransdata.cologneAC.itemSelectEvent.subscribe(cologneHandler);
function cologneHandler(s,a){
di.value = dktransdata.dk[a[2][0]];
}
All that is left is to do the same for the German to Cologne field:
dktransdata.germanDS = new YAHOO.util.LocalDataSource(
dktransdata.deutsch
);
dktransdata.germanDS.responseSchema = {fields:['term']};
dktransdata.germanAC = new YAHOO.widget.AutoComplete(
'deutschinput','deutschoutput',dktransdata.germanDS
);
dktransdata.germanAC.useShadow = true;
dktransdata.germanAC.itemSelectEvent.subscribe(germanHandler);
function germanHandler(s,a){
ci.value = dktransdata.kd[a[2][0]];
}
Step 5:Putting it all together
You can see the full source of the translation tool on GitHub and can download it there, too.
Of course we are not really finished here as this only works in JavaScript environments. As the translator was meant to be a widget though, this was not an issue. That the autocomplete does not seem to work on mobiles is one, though :).
Making this work without JavaScript would be pretty easy, too. As the data is returned in JSON we can also use this in PHP and write a simple form script If wanted, I can do that later.