Tutorial: scraping and turning a web site into a widget with YQL
Tuesday, August 25th, 2009 at 10:38 amDuring the mentoring sessions at last weekend’s Young Rewired State one of the most asked questions was how you can easily re-use content on the web. The answer I gave was by using YQL and I promised a short introduction to the topic so here it is. What we are going to do here and now is to turn a web sites into a widget with YQL and a few lines of JavaScript:
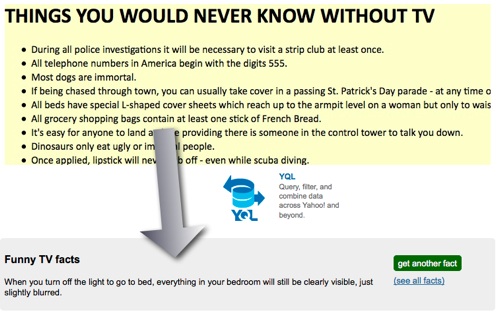
Say you have a web site with a list of content and you want to turn it into widget to include in other web sites. For example this list of funny TV facts (which is really a Usenet classic). The first thing you need to do with this is to find out its structure, either by looking at the source code of the page or by using Firebug:
Note: The original joke site is dead, so I fixed the widget to use another one. The concept still works though.

If you right-click on the item in Firebug you can get the XPATH to the element you want to reach – we’ll need this later. In this case the xpath is /html/body/ul/li[92] which gets us that single element. If we want all TV facts, then we need to shorten this to //ul/li.
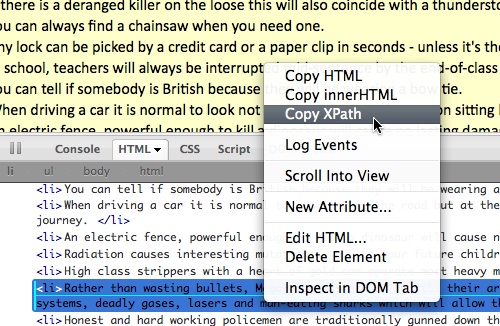
The next step is to go to the YQL console and enter the following statement.
select * from html where url='http://www.dcs.gla.ac.uk/~joy/fun/jokes/TV.html' and xpath='//ul/li'This follows the syntax select * from html where url='{url}' and xpath='{xpath}'. This will result in YQL pulling the page content and giving it back to us as XML:
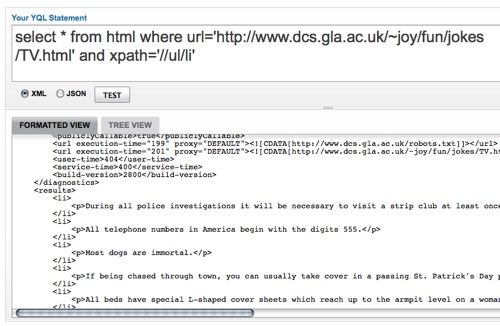
Notice that YQL has inserted P elements in the results. This is because YQL runs the XML through HTML Tidy to remove invalid HTML. This means that we need to alter our XPATH to be //ul/li/p to get to the texts.
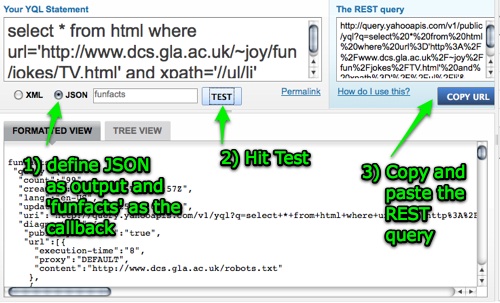
The next step is to define the output format as JSON, define a callback function with the name funfacts, hit the test button, wait for the results and copy and paste the REST query.
That’s all you need to do. You will now have the HTML as a JavaScript-readable object and all you need to do is to define a function called funfacts that gets the data from YQL and add another SCRIPT node with the REST URL you copied from YQL as the src attribute:
The function will get the data from YQL as you were able to see in the console. Therefore getting to the TV facts is as easy as accessing o.query.results.p.
The rest of the functionality is plain and simple DOM Scripting. Check the comments for explanations:
Funny TV facts
Add a bit of styling and you’ll end up with quite a cool little widget powered by the data on the jokes site. Check the source of the demo to see all the CSS needed.
That is all there is to it – get scraping!
Tags: development, javascript, scraping, widget, yql