Using YQL to read HTML from a document that requires POST data
Monday, November 16th, 2009YQL is a very cool tool to extract data from HTML documents on the web. Let’s face facts: HTML is a terrible data format as far too many documents out there are either broken, have a wrong encoding or simply are not structured the way they should be. Therefore it can be quite a mess to try to read a HTML document and then find what you were looking for using regular expressions or tools that expect XML compatible HTML documents. Python fans will know about beautiful soup for example that does quite a good job working around most of these issues.
Using YQL you can however use a simple web service to extract data from HTML documents. As an added bonus, the YQL engine will remove falsely encoded characters and run the data retrieved through HTML Tidy to get valid HTML back. For example to get the body content of CNN.com all you’d need to do is a:
select * from HTML where url="http://cnn.com" |
The really cool thing about YQL is that it allows you to XPATH to filter down the data you want to extract. For example to get all the links from cnn.com you can use:
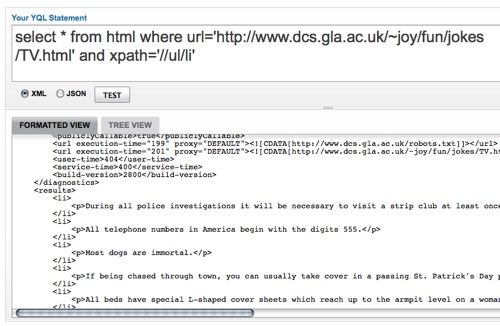
select * from html where xpath="//a" and url="http://cnn.com" |
If you only want to have the text content of the links you can do the following:
select content from html where xpath="//a" and url="http://cnn.com" |
You could use this for example to translate links using the Google translation API:
select * from google.translate where q in ( select content from html where url="http://cnn.com" and xpath="//a" ) and target="fr" |
Now, the other day my esteemed colleague Dirk Ginader came up with a bit of a brain teaser for me. His question was what to do when the HTML document you try to get needs POST data sent to it for it to render properly? You can append GET parameters to the URL, but not POST so the normal HTML document is not enough.
The good news is that YQL allows you to extend it in many ways, one of them is using an execute block in an open table to convert data with JavaScript on the server. The JavaScript has full e4x support and allows you to do any HTTP request. So the first step to solve Dirk’s dilemma was to write a demo page (the form was added to test it out):
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <html> <title>Test for HTML POST table</title> <body> <p>Below this should be a "yay!" when the right POST data was submitted.</p> <?php if(isset($_POST['foo']) && isset($_POST['bar'])){ echo "<p>yay!</p>"; }?> <form action="index.php" method="post" accept-charset="utf-8"> <input type="text" name="foo" value="is"> <input type="text" name="bar" value="set"> <input type="submit" value="Continue →"> </form> </body> </html> |
The next step was to write an open table for YQL that does the necessary request and transformations.
<?xml version="1.0" encoding="UTF-8"?> <table xmlns="http://query.yahooapis.com/v1/schema/table.xsd"> <meta> <author>Christian Heilmann</author> <description>HTML pages that need post data</description> <sampleQuery><![CDATA[ select * from {table} where url='http://isithackday.com/hacks/htmlpost/index.php' and postdata="foo=foo&bar=bar" and xpath="//p"]]></sampleQuery> <documentationURL></documentationURL> </meta> <bindings> <select itemPath="" produces="XML"> <urls> <url>{url}</url> </urls> <inputs> <key id="url" type="xs:string" required="true" paramType="variable"/> <key id="postdata" type="xs:string" required="true" paramType="variable"/> <key id="xpath" type="xs:string" required="true" paramType="variable"/> </inputs> <execute> <![CDATA[ var myRequest = y.rest(url); var data = myRequest.accept('text/html'). contentType("application/x-www-form-urlencoded"). post(postdata).response; var xdata = y.xpath(data,xpath); response.object = <postresult>{xdata}</postresult>; ]]> </execute> </select> </bindings> </table> |
Using this, you can now send POST data to any HTML document (unless its robots.txt blocks the YQL server or it needs authentication) and get the HTML content back. To make it work, you define the table using the “use” command:
use "http://isithackday.com/hacks/htmlpost/htmlpost.xml" as htmlpost;
select * from htmlpost where
url='http://isithackday.com/hacks/htmlpost/index.php'
and postdata="foo=foo&bar=bar" and xpath="//p" |
You can try this example in the console.
I’ve also added the table to the open YQL tables repository on github so it should show up sooner or later in the console.
Here’s a quick explanation what is going on:
<?xml version="1.0" encoding="UTF-8"?> <table xmlns="http://query.yahooapis.com/v1/schema/table.xsd"> <meta> <author>Christian Heilmann</author> <description>HTML pages that need post data</description> <sampleQuery><![CDATA[ select * from {table} where url='http://isithackday.com/hacks/htmlpost/index.php' and postdata="foo=foo&bar=bar" and xpath="//p"]]></sampleQuery> <documentationURL></documentationURL> </meta> |
You define the schema and add meta data like the author, a description and a sample query. The latter is really important as that will show up in the YQL console when people click the table. You should normally also provide a documentation URL, but this post wasn’t written when I wrote the table so I kept it empty.
<bindings> <select itemPath="" produces="XML"> <urls> <url>{url}</url> </urls> |
The bindings of the table describe the real API data endpoints the table points to. You have select, insert, update and delete – much like any other database. You provide an itemPath to cut down on the data returned and tell YQL if the data returned is XML or JSON.
<inputs> <key id="url" type="xs:string" required="true" paramType="variable"/> <key id="postdata" type="xs:string" required="true" paramType="variable"/> <key id="xpath" type="xs:string" required="true" paramType="variable"/> </inputs> |
The inputs section defines what variables are expected, if they are required and what their IDs are. These IDs will be available for you as variables in the embedded JavaScript block and are normally defined by the API your table points to.
<execute> <![CDATA[ var myRequest = y.rest(url); var data = myRequest.accept('text/html'). contentType("application/x-www-form-urlencoded"). post(postdata).response; var xdata = y.xpath(data,xpath); response.object = <postresult>{xdata}</postresult>; ]]> </execute> |
Here comes the JavaScript magic inside the execute block. The y.rest(url) command sends a REST query to the URL. in the easiest form this would just mean to get the data back but in our case we need to define a few more things. We expect html back so we set the request accept header to text/html. This also ensures that the result is run through HTML Tidy before it is returned. The content type has to be like a form submission and we need to send the string postdata as a post request. The response then contains whatever our request brings back.
As we want to have the handy functionality of the original HTML table, we also need to do an xpath transformation which is done with the method of the same name.
Any JavaScript in the execute block needs to define a response.object which will become the result of the YQL query. As you can see, the E4X support of YQL allows you to simply write XML blocks without any DOM pains and you can embed any JavaScript variables inside curly braces.
</select> </bindings> </table> |
And we’re done. Using YQL execute you can move a lot of JavaScript that does complex transformations to the Yahoo server farm without slowing down your end user’s computers. And you have a secure environment to boot as there are no DOM vulnerabilities.


 ';
$href = 'http://www.flickr.com/photos/'.$o->nsid.'/'.$a->id;
$out.= '
';
$href = 'http://www.flickr.com/photos/'.$o->nsid.'/'.$a->id;
$out.= ' ';
} else {
$out.= '
';
} else {
$out.= ' ';
}
$out.= '
';
}
$out.= ' ';
YAHOO.util.Event.preventDefault(e);
});
YAHOO.util.Event.on('content','click',function(e){
var t = YAHOO.util.Event.getTarget(e);
if(t.nodeName.toLowerCase()==='img'){
var str = '
';
YAHOO.util.Event.preventDefault(e);
});
YAHOO.util.Event.on('content','click',function(e){
var t = YAHOO.util.Event.getTarget(e);
if(t.nodeName.toLowerCase()==='img'){
var str = '