Building a hack using YQL, Flickr and the web – step by step
Wednesday, March 11th, 2009 at 3:46 pmAs you probably know, I am spending a lot of time speaking and mentoring at hack days for Yahoo. I go to open hack days, university hack days and even organized my own hackday revolving around accessibility last year.
One of the main questions I get is about technologies to use. People are happy to find content on the web, but getting it and mixing it with other sources is still a bit of an enigma.
Following I will go through a hack I prepared at the Georgia Tech University hack day. I am using PHP to retrieve information of the web, YQL to filter it to what I need and YUI to do the CSS layout and add extra functionality.
The main ingredient of a good hack – the idea
I give a lot of presentations and every time I do people ask me where I get the pictures I use from. The answer is Flickr and some other resources on the internet. The next question is how much time I spend finding them and that made me think about building a small tool to make this easier for me.
This is how Slidefodder started and following is a screenshot of the hack in action. If you want to play with it, you can download the Slidefodder source code.
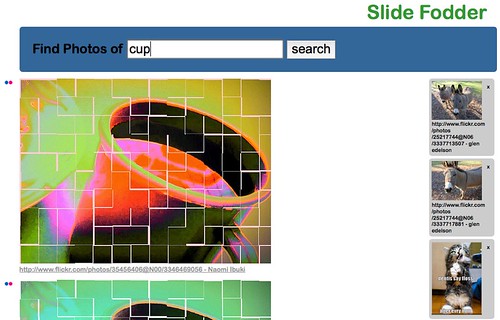
Step 1: retrieving the data
The next thing I could have done is deep-dive into the Flick API to get photos that I am allowed to use. Instead I am happy to say that using YQL gives you a wonderful shortcut to do this without brooding over documentation for hours on end.
Using YQL I can get photos from flickr with the right license and easily display them. The YQL statement to search photos with the correct license is the following:
select id from flickr.photos.search(10) where text='donkey' and license=4
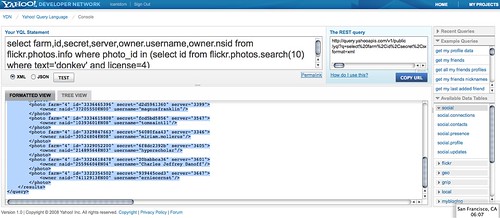
You can try the flickr YQL query here and you’ll see that the result (once you’ve chosen JSON as the output format) is a JSON object with photo results:
{
"query": {
"count": "10",
"created": "2009-03-11T01:23:00Z",
"lang": "en-US",
"updated": "2009-03-11T01:23:00Z",
"uri": "http://query.yahooapis.com/v1/yql?q=select+*+from+flickr.photos.search%2810%29+where+text%3D%27donkey%27+and+license%3D4",
"diagnostics": {
"publiclyCallable": "true",
"url": {
"execution-time": "375",
"content": "http://api.flickr.com/services/rest/?method=flickr.photos.search&text=donkey&license=4&page=1&per_page=10"
},
"user-time": "376",
"service-time": "375",
"build-version": "911"
},
"results": {
"photo": [
{
"farm": "4",
"id": "3324618478",
"isfamily": "0",
"isfriend": "0",
"ispublic": "1",
"owner": "25596604@N04",
"secret": "20babbca36",
"server": "3601",
"title": "donkey image"
}
[...]
]
}
}
}
The problem with this is that the user name is not provided anywhere, just their Flickr ID. As I wanted to get the user name, too, I needed to nest a YQL query for that:
select farm,id,secret,server,owner.username,owner.nsid from flickr.photos.info where photo_id in (select id from flickr.photos.search(10) where text='donkey' and license=4)
This gives me only the information I really need (try the nested flickr query here):
{
"query": {
"count": "10",
"created": "2009-03-11T01:24:45Z",
"lang": "en-US",
"updated": "2009-03-11T01:24:45Z",
"uri": "http://query.yahooapis.com/v1/yql?q=select+farm%2Cid%2Csecret%2Cserver%2Cowner.username%2Cowner.nsid+from+flickr.photos.info+where+photo_id+in+%28select+id+from+flickr.photos.search%2810%29+where+text%3D%27donkey%27+and+license%3D4%29",
"diagnostics": {
"publiclyCallable": "true",
"url": [
{
"execution-time": "394",
"content": "http://api.flickr.com/services/rest/?method=flickr.photos.search&text=donkey&license=4&page=1&per_page=10"
},
[...]
],
"user-time": "1245",
"service-time": "4072",
"build-version": "911"
},
"results": {
"photo": [
{
"farm": "4",
"id": "3344117208",
"secret": "a583f1bb04",
"server": "3355",
"owner": {
"nsid": "64749744@N00",
"username": "babasteve"
}
}
[...]
}
]
}
}
}
The next step was getting the data from the other resources I am normally tapping into: Fail blog and I can has cheezburger. As neither of them have an API I need to scrape the HTML data of the page. Luckily this is also possible with YQL, all you need to do is select the data from html and give it an XPATH. I found the XPATH by analysing the page source in Firebug:

This gave me the following YQL statement to get images from both blogs. You can list several sources as an array inside the in() statement:
select src from html where url in ('http://icanhascheezburger.com/?s=donkey','http://failblog.org/?s=donkey') and xpath="//div[@class='entry']/div/div/p/img"
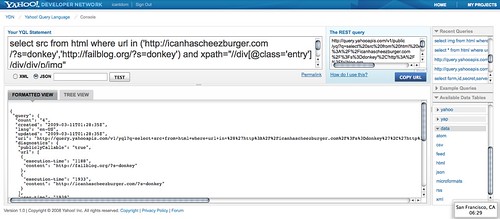
The result of this query is again a JSON object with the src values of photos matching this search:
{
"query": {
"count": "4",
"created": "2009-03-11T01:28:35Z",
"lang": "en-US",
"updated": "2009-03-11T01:28:35Z",
"uri": "http://query.yahooapis.com/v1/yql?q=select+src+from+html+where+url+in+%28%27http%3A%2F%2Ficanhascheezburger.com%2F%3Fs%3Ddonkey%27%2C%27http%3A%2F%2Ffailblog.org%2F%3Fs%3Ddonkey%27%29+and+xpath%3D%22%2F%2Fdiv%5B%40class%3D%27entry%27%5D%2Fdiv%2Fdiv%2Fp%2Fimg%22",
"diagnostics": {
"publiclyCallable": "true",
"url": [
{
"execution-time": "1188",
"content": "http://failblog.org/?s=donkey"
},
{
"execution-time": "1933",
"content": "http://icanhascheezburger.com/?s=donkey"
}
],
"user-time": "1939",
"service-time": "3121",
"build-version": "911"
},
"results": {
"img": [
{
"src": "http://icanhascheezburger.files.wordpress.com/2008/09/funny-pictures-you-are-making-a-care-package-very-correctly.jpg"
},
{
"src": "http://icanhascheezburger.files.wordpress.com/2008/01/funny-pictures-zebra-donkey-family.jpg"
},
{
"src": "http://failblog.files.wordpress.com/2008/11/fail-owned-donkey-head-intimidation-fail.jpg"
},
{
"src": "http://failblog.files.wordpress.com/2008/03/donkey.jpg"
}
]
}
}
}
Writing the data retrieval API
The next thing I wanted to do was writing a small script to get the data and give it back to me as HTML. I could have used the JSON output in JavaScript directly but wanted to be independent of scripting. The script (or API if you will) takes a search term, filters it and executes both of the YQL statements above before returning a list of HTML items with photos in them. You can try it out for yourself: search for the term donkey or search for the term donkey and give it back as a JavaScript call
I use cURL to get the data as my server has external pulling of data via PHP disabled. This should work for most servers, actually.
Here’s the full “API” code:
';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $flickurl);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
$flickrphotos = json_decode($output);
foreach($flickrphotos->query->results->photo as $a){
$o = $a->owner;
$out.= ' '.
'
'.
' ';
$href = 'http://www.flickr.com/photos/'.$o->nsid.'/'.$a->id;
$out.= ''.$href.' - '.$o->username.'
';
$href = 'http://www.flickr.com/photos/'.$o->nsid.'/'.$a->id;
$out.= ''.$href.' - '.$o->username.'';
if(strpos($a->src,'failblog') = 7){
$out.= ' ';
} else {
$out.= '
';
} else {
$out.= ' ';
}
$out.= '
';
}
$out.= '
';
}
$out.= '';
if($_GET['js']=’yes’){
$out.= ‘’})’;
}
echo $out;
} else {
echo ($_GET[‘js’]!==’yes’) ?
‘Invalid search term.
’ :
‘seed({html:”Invalid search Term!”})’;
}
}
?>
Let’s go through it step by step:
I test if the js parameter is set and if it is I send a JavaScript header and start the JS object output.
if(isset($_GET['s'])){
$s = $_GET['s'];
if(preg_match("/^[0-9|a-z|A-Z|-| |+|.|_]+$/",$s)){
I get the search term and filter out invalid terms.
$flickurl = 'http://query.yahooapis.com/v1/public/yql?q=select'.
'%20farm%2Cid%2Csecret%2Cserver%2Cowner.username'.
'%2Cowner.nsid%20from%20flickr.photos.info%20where%20'.
'photo_id%20in%20(select%20id%20from%20'.
'flickr.photos.search(10)%20where%20text%3D''.
$s.''%20and%20license%3D4)&format=json';
$failurl = 'http://query.yahooapis.com/v1/public/yql?q=select'.
'%20*%20from%20html%20where%20url%20in'.
'%20('http%3A%2F%2Ficanhascheezburger.com'.
'%2F%3Fs%3D'.$s.''%2C'http%3A%2F%2Ffailblog.org'.
'%2F%3Fs%3D'.$s.'')%20and%20xpath%3D%22%2F%2Fdiv'.
'%5B%40class%3D'entry'%5D%2Fdiv%2Fdiv%2Fp%2Fimg%22%0A&'.
'format=json';
These are the YQL queries, you get them by clicking the “copy url” button in YQL.
$out.= '';
I then start the output list of the results.
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $flickurl);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
$flickrphotos = json_decode($output);
foreach($flickrphotos->query->results->photo as $a){
$o = $a->owner;
$out.= ''.
'';
$href = 'http://www.flickr.com/photos/'.$o->nsid.'/'.$a->id;
$out.= ''.$href.' - '.$o->username.' ';
}
I call cURL to retrieve the data from the flickr yql query, do a json_decode and loop over the results. Notice the rather annoying way of having to assemble the flickr url and image source. I found this by clicking around flickr and checking the src attribute of images rendered on the page. The images with the “ico” class should tell me where the photo was from.
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $failurl);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
$failphotos = json_decode($output);
foreach($failphotos->query->results->img as $a){
$out.= '';
if(strpos($a->src,'failblog') = 7){
$out.= '';
} else {
$out.= '';
}
$out.= ' ';
}
Retrieving the blog data works the same way, all I had to do extra was check for which blog the resulting image came from.
$out.= '';
if($_GET['js']=’yes’){
$out.= ‘’})’;
}
echo $out;
I close the list and – if JavaScript was desired – the JavaScript object and function call.
} else {
echo ($_GET['js']!=='yes') ?
'Invalid search term.
' :
'seed({html:"Invalid search Term!"})';
}
}
?>
If there was an invalid term entered I return an error message.
Setting up the display
Next I went to the YUI grids builder and created a shell for my hack. Using the generated code, I added a form, my yql api, an extra stylesheet for some colouring and two IDs for easy access for my JavaScript:
Slide Fodder - find CC licensed photos and funpics for your slides
Slide Fodder
Slide Fodder by Christian Heilmann, hacked live at Georgia Tech University Hack day using YUI and YQL.
Photo sources: Flickr, Failblog and I can has cheezburger.
Rounding up the hack with a basket
The last thing I wanted to add was a “basket” functionality which would allow me to do several searches and then copy and paste all the photos in one go once I am happy with the result. For this I’d either have to do a persistent storage somewhere (DB or cookies) or use JavaScript. I opted for the latter.
The JavaScript uses YUI and is no rocket science whatsoever:
function seed(o){
YAHOO.util.Dom.get('content').innerHTML = o.html;
}
YAHOO.util.Event.on('f','submit',function(e){
var s = document.createElement('script');
s.src = 'yql.php?js=yes&s='+ YAHOO.util.Dom.get('s').value;
document.getElementsByTagName('head')[0].appendChild(s);
YAHOO.util.Dom.get('content').innerHTML = ' ';
YAHOO.util.Event.preventDefault(e);
});
YAHOO.util.Event.on('content','click',function(e){
var t = YAHOO.util.Event.getTarget(e);
if(t.nodeName.toLowerCase()==='img'){
var str = '
';
YAHOO.util.Event.preventDefault(e);
});
YAHOO.util.Event.on('content','click',function(e){
var t = YAHOO.util.Event.getTarget(e);
if(t.nodeName.toLowerCase()==='img'){
var str = ' ';
if(t.src.indexOf('flickr')!==-1){
str+= '
';
if(t.src.indexOf('flickr')!==-1){
str+= ''+t.parentNode.getElementsByTagName('a')[0].innerHTML+'
';
}
str+='x';
YAHOO.util.Dom.get('basket').innerHTML+=str;
}
YAHOO.util.Event.preventDefault(e);
});
YAHOO.util.Event.on('basket','click',function(e){
var t = YAHOO.util.Event.getTarget(e);
if(t.nodeName.toLowerCase()==='a'){
t.parentNode.parentNode.removeChild(t.parentNode);
}
YAHOO.util.Event.preventDefault(e);
});
Again, let’s check it bit by bit:
function seed(o){
YAHOO.util.Dom.get('content').innerHTML = o.html;
}
This is the method called by the “API” when JavaScript was desired as the output format. All it does is change the HTML content of the DIV with the id “content” to the one returned by the “API”.
YAHOO.util.Event.on('f','submit',function(e){
var s = document.createElement('script');
s.src = 'yql.php?js=yes&s='+ YAHOO.util.Dom.get('s').value;
document.getElementsByTagName('head')[0].appendChild(s);
YAHOO.util.Dom.get('content').innerHTML = '![]() ';
YAHOO.util.Event.preventDefault(e);
});
';
YAHOO.util.Event.preventDefault(e);
});
When the form (the element with th ID “f”) is submitted, I create a new script element,give it the right src attribute pointing to the API and getting the search term and append it to the head of the document. I add a loading image to the content section and stop the browser from submitting the form.
YAHOO.util.Event.on('content','click',function(e){
var t = YAHOO.util.Event.getTarget(e);
if(t.nodeName.toLowerCase()==='img'){
var str = '';
if(t.src.indexOf('flickr')!==-1){
str+= ''+t.parentNode.getElementsByTagName('a')[0].innerHTML+'
';
}
str+='x';
YAHOO.util.Dom.get('basket').innerHTML+=str;
}
YAHOO.util.Event.preventDefault(e);
});
I am using Event Delegation to check when a user has clicked on an image in the content section and create a new DIV with the image to add to the basket. When the image was from flickr (I am checking the src attribute) I also add the url of the image source and the user name to use in my slides later on. I add an “x” link to remove the image from the basket and again stop the browser from doing its default behaviour.
YAHOO.util.Event.on('basket','click',function(e){
var t = YAHOO.util.Event.getTarget(e);
if(t.nodeName.toLowerCase()==='a'){
t.parentNode.parentNode.removeChild(t.parentNode);
}
YAHOO.util.Event.preventDefault(e);
});
In the basket I remove the DIV when the user clicks on the “x” link.
That’s it
This concludes the hack. It works, it helps me get photo material faster and it took me about half an hour to build all in all. Yes, it could be improved in terms of accessibility, but this is enough for me and my idea was to show how to quickly use YQL and YUI with a few lines of PHP to deliver something that does a job :)