I have just returned from Toronto, Canada where I spoke at the second Domain Convergence conference about web development with distributed data and about using the social web.
First of all I have to say that this was an eye-opening experience for me as I never even knew that there is a whole community of “Domainers” – people who buy, sell and “develop” internet domains much like other people do with real estate.
The organisers (an old friend of mine hailing back from the time when we created C64 demos together) wanted me to talk about web development with APIs and the social web as the current state of this in the domain market is very much random. The common way of creating some content for a domain is to hire a developer on rent-a-coder, get a $99 logo, write some content and put it live. The main goal for the site thus created is to make people click the ads on it – selling the domain is secondary step.
This is totally the opposite of what I consider web development but instead of condemning it I loved to get the opportunity to show another way of building web sites on a very small budget and without much technical know how. This is what I had to say:
The presentation SlideCast
Notes
Following are the notes that I was meant to say during the presentation. I ad-lib a lot though. Can’t help it, eh?
Developing with the web
The current financial crisis is reported to have its toll on the web business as well. Whilst that is true to a degree (declining ad sales show that) there might be a different reason though: the web moves on and so do the habits of our users.
Build it and they will come doesn’t cut it any more
Anybody who builds a web product and wonders why there are less and less comments, visits and clicks must realise that they are part of a massive network of sites and offers. People use the web and multi-task their social interactions.
Back when this was all fields
I remember that back when I started as a web developer you had one browser window. If you wanted to have several pages open you needed several windows. All of these used up memory of which we didn’t have much. As computers were slow we maybe had another chat client open or an IRC client and an email client. In any case, working and surfing were two different tasks.
The web 2.0 revolution
With web 2.0 this changed. Computers became more powerful, browsers started supporting multiple tabs and software moved from bulky desktop to lighter web-based interfaces. The web turned from a read to a read/write media and its users started actively defining their web experience by altering it rather than just reading online content.
Bring the noise!
The next wave was more and more social networks, blogging, micro-blogging and messaging systems. As humans we are hard-wired to communicate and tell the world about everything we do. Only our social standards and learned manners changed that. As neither seems to be of much significance on the web we are happy to tell the world what we do – no matter if the world is interested or not. After all, once we found something out and told the world about it it is time to go back and find the next big thing.
Oh, shiny object!
This wealth of real-time information causes an overload and makes people easily distracted. It also cheapens communication and forces us to give more and more information in shorter and more to-the-point formats.
If you can’t fight them…
Enough complaining though. The funny thing is that the distributed web we have right now is exactly what the web should be like. Web sites are not radio or TV channels – they are small data sets that tie in with a much larger network of data. So in order to be part of this we need to distribute our content.
Spreading and collecting
The way to have fun with the web of data is to distribute ourselves around the web and bring the data back to our sites.
The first step is to spread our content on the web:
The benefits of this approach are the following:
- The data is distributed over multiple servers – even if your own web site is offline (for example for maintenance) the data lives on
- You reach users and tap into communities that would never have ended up on your web site.
- You get tags and comments about your content from these sites. These can become keywords and guidelines for you to write very relevant copy on your main site in the future. You know what people want to hear about rather than guessing it.
- Comments on these sites also mean you start a channel of communication with users of the web that happens naturally instead of sending them to a complex contact form.
- You don’t need to worry about converting image or video materials into web formats – the sites that were built exactly for that purpose automatically do that for you.
- You allow other people to embed your content into their products and can thus piggy-back on their success and integrity.
If you want to more about this approach, check out the Developer Evangelism Handbook where I cover this in detail in the “Using the (social) web” chapter.
Bringing the web to the site
The other thing to think about is to bring the web to the site and allow people to use the services they are happy to use right in your interface.
One of the main things I found to be terribly useful there is Chat Catcher. Chat Catcher is a wordpress plug-in or PHP script that checks various social networks for updates that link to your web site. That way you can get for example Twitter updates with links to your site as comments on your blog. This showed me just how much people talk about my posts although I didn’t get many comments. The only small annoyance is that re-tweets show up but that can be tweaked.
Another interesting small tool is Yahoo Sideline which allows you to define searches for the Twitter network, get automatic updates and answer the tweets.
Cotweet does the same thing but on a much more professional level. Cotweet was build for corporations to manage their Twitter outreach and it helps you not only to track people talking about certain topics but also to define “shifts” for several people to monitor Twitter during a certain time period. Using this in a company with offices in various parts of the world you can have a 24 hour Twitter coverage without having to log in from several locations to Twitter itself.
Another way to take advantage of the social web is to allow visitors of your web site to update their status on various social networks directly from your site. This could be as easy as adding a “tweet this” or “bookmark this in delicious” button or as complex as implementing third party widgets like on the new Yahoo homepage.
Digging into the web of data.
Bringing the social web to your site is the first step. Using information of the “web of data” in your site is much more powerful, but also a bit more complex to accomplish.
Getting to the juicy, yummy data
The web is full of nice and juicy data and there is a lot of it around. Our attempts to get to it can be quite clumsy though. What we need is a simple way to access that data. One classic way of doing that is Yahoo Pipes.
Yahoo Pipes is a visual interface to remix information from various data sources like web sites and RSS feeds. The interface reminds the user of visio or database organising tools and is very easy to use. The issue with pipes is that it is a high tech interface (users who can’t see or cannot use a mouse have no way of using it) and it is hard to change a pipe. Any change means that you need to get back to the pipes interface and visually change the structure of the pipe. The good news is that you can clone other people’s pipes and learn from that.
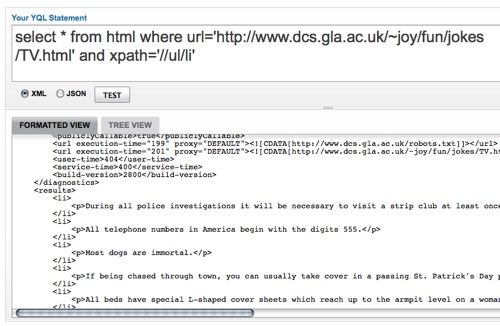
A much easier and more flexible way of mixing the web is YQL. The Yahoo Query Language, or short YQL is a unified interface language to the web. The syntax is as easy as very plain SQL:
select {what} from {service} where {condition}
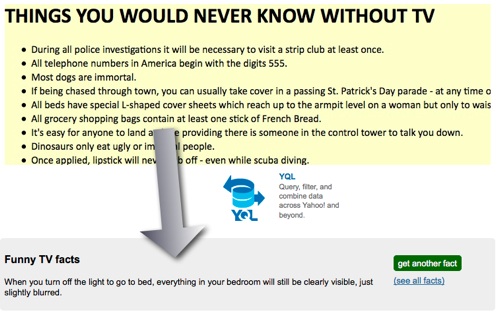
Say for example you want kittens on your site (who doesn’t?) the following YQL statement would grab photos with the word “kitten” in the description, title or tags from Flickr.
select * from flickr.photos.search where text="kitten"
Say you only want 5 kittens – all you need to do is add a limit command:
select * from flickr.photos.search where text="kitten" limit 5
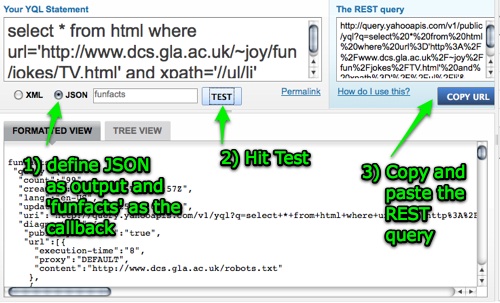
Nice, but where can you get this? YQL is an API in itself and has a URL endpoint:
http://query.yahooapis.com/v1/public/yql?q={query}&format={format}
Output formats are either XML or JSON. If you choose JSON you can use use the data immediately in JavaScript.
Re-mixing the web.
You can nest several YQL queries to do complex web lookups. Guess what this does:
select * from flickr.photos.info where photo_id in (
select id from flickr.photos.search where woe_id in (
select woeid from geo.places where text='london,uk'
) and license=4
)
What this does is:
- Find London, England using the places API of the Yahoo Geo platform. This is needed to make sure you really find photos that were taken in London, England and not for example of a band called London. The Geo places API returns a place as a where on earth or short woe ID.
- Search Flickr photos that have this where on earth ID
- Get detailed information for each photo found in Flickr.
- Only return photos that have a license of 4 as this means the photos are creative commons and you are allowed to use them. This is extremely important as Flickr users can be very protective about their photos.
Display them using free widgets!
You can use systems like the Yahoo User Interface Library to display the photos you found easily in a nice interface.
Using several APIs via YQL and the YUI CSS grids you can show for example information about a certain location without having to maintain any of the content yourself. This example about Frankfurt,Germany shows what this might look like. This page automatically updates itself every time the wikipedia entry of frankfurt is changed or somebody uploads a new photo of Frankfurt, the weather changes in the Yahoo weather API or somebody adds a new event happening in Frankfurt.
All of this works using APIs
The driver behind all these things are Application Programming Interfaces or short APIs. An API is a way to get to the information that drives a web site on a programmatic level and a chance to remix that information. Say for example you want the currently trending topics on Twitter. You can either go to the Twitter homepage or you can open the following URL in a browser:
This will give you the currently trending topics in JSON format – something you can easily convert and use.
API issues
There are of course a few issues with APIs. First of all, there are a lot of them out there. Programmable Web, a portal trying to keep up with the release and demise of APIs currently lists over 1400 different APIs. This is great but the issue is that most of them don’t follow any of the structure of others. Authentication, input and output parameters and access limitations vary from API to API and can make it hard for us to use them. This is where YQL comes in as an easy way out.
The other issue with APIs is that they might only be experimental and can get shut down or change even without warning. Therefore you need to write very defensive code to read out APIs. Expect everything to fail and keep local copies of the data to display should for example Twitter be offline again for a day.
Conjuring content?
The generation of content-rich web products without having to write the content yourself sounds like a dream come true. It is important though to keep reminding us that we use other people’s content and that we are relying on them to deliver it.
Content issues
Whilst you can automate a lot it remains a very good idea to have a human check third party content before putting it live. All kind of things can go wrong – bad encoding can make the text look terrible, a hickup in the CMS can seed wrong content into the category you chose, texts can bee too large to display and many other factors. Therefore it is a good idea to write a validation tool to shorten text and resize images in the data you pull.
Lack of context
One usability issue is that there might be a lack of context. Earlier we showed that it is important to distinguish between a geographical location like Paris, France and a person like Paris Hilton. The same applies to content you get from the web. People are happy to share their content but can get very cross when you display it next to things they do not approve of. Remember that people publish data on the web out of the good of their heart. Don’t cheapen this by displaying information out of context.
UGC issues
One thing professional journalists and writers have been critising for a long time is that while there is a lot of immediacy in user generated content there is also a lack of quality control. Sadly enough in a lot of cases the people that are most driven to state their opinion are the least appropriate ones to do so. Comments can be harsh and make people stop believing in web2.0 as a means of telling people your thoughts. The trick is to take the good with the bad. For you this means once again that the amount of UGC data is not what you should measure – the quality is what you need to care about.
Placement
Bad placement can cheapen the whole idea of the web of data. If you for example show photos of laptops of a certain brand next to news that these models are prone to explode or die one day after warranty expiration you won’t do yourself any favour. Again, showing people’s reviews and blog posts next to bad news might also get them cross.
Legal issues
Which brings us to legal issues. Just because data is available on the web doesn’t naturally mean that you can use it. You can have a lot of free data on the web and use it to make the now more or less useless parking sites for domains more valuable to the reader. You do however also need to make sure that you are allowed to use that content and that you display it with the right attribution.
Demos and resources
Here are a few things to look at that any developer can use and build with a bit of effort.
- My portfolio page is completely driven by YQL and maintained outside the server. If I want to upgrade it, I either post something on my blog, change some of the blog pages, add new bookmarks to delicious or upload new slides to SlideShare
- Keyword Finder uses the Yahoo BOSS API to find related keywords to any item you enter. The keywords are the keywords that real users entered to reach the top 20 results in a Yahoo search
- YSlow is a Firefox add-on that allows you to analyse why your web site is slow and what can be done to make it more nimble and thus create happier visitors.
- GeoMaker is a tool build on Yahoo Placemaker to find geographical locations in texts and turn them into maps or embeddable microformats.
- Blindsearch is a side-by-side comparison of Yahoo, Bing and Google search results and thus a fast way to find out how you rank on all three.
- Correlator is an experiment in alternative search interfaces. Instead of getting a catch-all search result page you can filter the results by interests, locations or people.
- The developer evangelism handbook is a free online book I’ve written and in this chapter I go into more detail about the subjects covered here.
- Web Development Solutions is a book I’ve published with Friends of Ed dealing with the subject of web development using distributed data.
Play nice!
As one of the last things I want to remind you that it is important to play nice on the social web. It is all about giving, sharing and connecting and if you abuse the system people will complain about you and cause a stir that is very hard to counter with PR or marketing. If you however embrace the social aspect of the web you can have quite an impact as the following example shows.
Colalife.org
Colalife is a great example how using the social web can have an impact on the life of people. The organisers of colalife used the social web (Facebook and Twitter) to persuade Coca Cola to ship free medication with their drinks into third world countries. Coca Cola has world-wide distribution channels with chilled storage and the Colalife people designed a special device that would allow to store contraceptives and rehydration medication in bottle crates without taking up extra space. Coca Cola agreed and now medication is delivered to those who need it for free and the company creates a ton of good will. It was one person with an idea and a network of millions to freely tell a corporation about it that made it happen.
Thanks!
That’s all I wanted to talk about, thanks.
Extra achivement
As an extra, I am happy to announce that because of my inventiveness in ordering drinks the Radisson Hotel in Toronto now offers a new cocktail of my invention called “keylime pie” which consists of Smirnoff Vanilla, Sour Mix and Soda. This was another first for me – I never had any of my inventions featured on a cocktail bar menu!


 In the last few days the blogosphere was abuzz and Twiter a-twitter about
In the last few days the blogosphere was abuzz and Twiter a-twitter about