New Twitter exploit about goats – how it works.
Sunday, September 26th, 2010OK, in the last few minutes you will have gotten a few tweets of people explaining that they like to have intercourse through the backdoor with goats. This is a Twitter exploit – probably initiated by someone doing a security talk (I know some people who would be devious enough).
The exploit is actually easy – the main ingredients are:
- Twitter allowing updates through the API via IFRAMES and GET thus being vulnerable to CSRF attacks
- PasteHTML.com being vulnerable to render code without a secure site around it and executing it
- Clients or Twitter automatically applying the t.co link shortener
The code to execute the “worm” is hosted at http://pastehtml.com/view/1b7xk3b.html so Twitter should contact them – (I just did):
Nothing magical there – all you do is create two SCRIPT files that point to the twitter update API and send a request to do an post. As the user who clicked on the malicious link is authenticated with twitter you can send them on his behalf. It is the same trick that worked for the “Don’t click this button” exploit or my demo at Paris Web last year how to get the updates of a protected Twitter user.
The effects of this are a mixed bag
- Bad: People stop trusting the t.co shortener after it was actually installed to be a trustworthy link shortener. The link shortening service is not compromised – this is one thing that can’t be blamed on Twitter
- Bad: There is a flood of wrong messages on Twitter
- Good: people talk about the exploit and how it was done
- Good: people get more conscious about clicking links
- Good: Twitter have to harden their API agains CSRF
- Bad: this will break some implementations
There is no real defense against CSRF from a user’s point of view other than not clicking links you don’t trust and turning off JavaScript. As this is a wide definition, we will get those over and over again unless API providers disallow for requests without tokens. This, on the flipside means that implementing one click solutions to tweet or like will be a lot harder.
I fell for the trick, too – especially as I didn’t expect PasteHTML to render code instead of sanitizing it.
Update: As some clever clogs just pointed out in the comments, JSBin is also vulnerable to hosting code that will be executed. One thing I do to check malicious links is to use curl in the terminal:
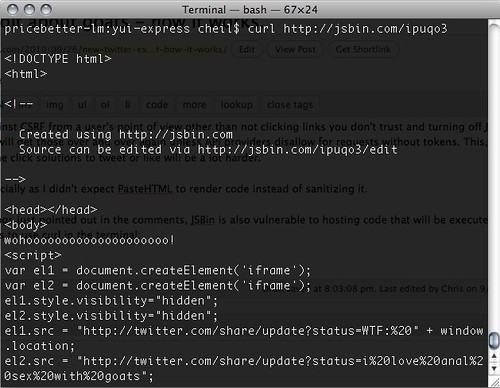
If you don’t know JS, that doesn’t help you but if you do you can warn the world.







{kind=link}