News Mixer – my first attempt at using the Guardian’s open platform content API
Tuesday, March 10th, 2009I am a very happy bunny at the moment. First of all because there is more yummy data on the web to play with as The Guardian just released a brand new API to access their archives and secondly as I was invited to play with it before it was public. The announce of the API was today and I’ve spent a few hours yesterday in my hotel room before checking out to build news mixer
The API is simple enough to use and once you got your developer key you can search for content and request the more detailed data using a content ID. The next problem to tackle was what to build.
Access of data and tags is easy
I love that we turned the web from yet another information channel into a read/write web and that user generated content allows us to get information from everybody and not just from dedicated journalists. I also love that you can tag information and make it easier to find that way. Lastly I love that with products like BOSS you can now get access to information of search engines and use that in your own sites.
Relevancy of tags?
The tagging bit has me a bit annoyed though. While a few years ago when the idea was still fresh people tagged like mad and with high quality keywords this seemed to be on the decline a bit and as faster connections allow us to upload more and more data in bulk people stopped tagging sensibly and rely more on automated tags like geolocation or exif data in images.
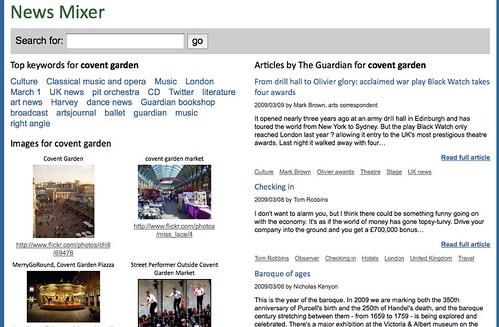
Mixing user tags and professional categories
I wanted to show a news site that allows you to find keywords that match your search term that make sense and used two different APIs for that. BOSS allows you to search for news items and images and the BOSS web search also offers keyterms for certain web sites. These keyterms are to a degree user generated as this is what people entered into Yahoo to find the sites. I then used the new Guardian Data API to pull relevant articles and as these are professionally tagged by journalists this makes for more relevant keywords. Putting the two together means a good mix of professional and up-to-date information.
The outcome is News Mixer and you can download the source code to play with it yourself.
It was amazingly straight forward to build, the only snags I hit were the following:
- Whilst BOSS provides keyterms for web searches, it does not do so for news searches. Therefore I used YQL to get the keyterms of each of the urls returned by news search in a nested loop. This is a bit hacky and I would love for that to change.
- The Guardian API returns articles by relevancy and not by date. You can specify though that you want articles before or after a certain date, which is why all I had to do is get the current date and go back one month from that.
- The content body of the Guardian API does not provide any paragraph or list information. This is very annoying as it results in terrible display (a massive chunk of text). I’ve worked around the issue by splitting the content at full stops and then injecting paragraphs after every third of them but that is just guesswork and not real structure of text.
In any case I am happy to have such a cool new archive of information to play with and we’re working on open table definitions for YQL to make it easy for you to get to the goodies the Guardian offers us.
