 Ok, using YQL and playing around with the console can make you go a bit too far.
Ok, using YQL and playing around with the console can make you go a bit too far.
A few days ago and in response to my 24 ways article on YQL my friend Jens Grochtdreis asked me how to get the thumbnails and some other data from the Slideshare site in one YQL request. He tried multiple XPATH filtering until I pointed out that there is a perfectly valid RSS feed with thumbnails.
That made we wonder why we really have to care about the detection of a feed but instead use it when it is there and let the computer do the detection for us. What I wanted to do was to turn the following HTML automatically into a list with the feed data as embedded lists:
The ungodly YQL request I came up with was the following:
select
title,link,content.thumbnail,thumbnail,description
from feed where url in (
select href from html where url in (
"http://wait-till-i.com",
"http://flickr.com/photos/codepo8",
"http://slideshare.com/cheilmann",
"http://youtube.com/chrisheilmann"
) and
xpath="//link[contains(@type,'rss')][1]")
|unique(field="link")
What is going on here? I am using the html table to read in each of the resources I want to analyse:
select * from html where url in (
"http://wait-till-i.com",
"http://flickr.com/photos/codepo8",
"http://slideshare.com/cheilmann",
"http://youtube.com/chrisheilmann"
)
Then I use xpath and return the first link element that has a type attribute that contains the word RSS. In YQL I only take its href attribute.
select href from html where url in (
"http://wait-till-i.com",
"http://flickr.com/photos/codepo8",
"http://slideshare.com/cheilmann",
"http://youtube.com/chrisheilmann"
) and
xpath="//link[contains(@type,'rss')][1]")
Notice the joy that is xpath syntax… 0 is the first – every developer knows that! We then use the feed table to get the feed information from each of these hrefs as urls:
select
title,link,content.thumbnail,thumbnail,description
from feed where url in (
select href from html where url in (
"http://wait-till-i.com",
"http://flickr.com/photos/codepo8",
"http://slideshare.com/cheilmann",
"http://youtube.com/chrisheilmann"
) and
xpath="//link[contains(@type,'rss')][1]")
The last thing that was a problem is that Flickr returns the photo items several times that way as it has a feed for the url of the photo and one for the link to the license of the photo. Therefore we needed to use unique() to get only the first of these:
select
title,link,content.thumbnail,thumbnail,description
from feed where url in (
select href from html where url in (
"http://wait-till-i.com",
"http://flickr.com/photos/codepo8",
"http://slideshare.com/cheilmann",
"http://youtube.com/chrisheilmann"
) and
xpath="//link[contains(@type,'rss')][1]")
|unique(field="link")
So, this actually does what we want – we have all the different requests in one HTTP request and then only need some JavaScript to display it. The data coming back is a mess, as it is just an array of items – so we need to loop and check the link of each to know when to go to the next list item.
This is very quick and dirty:
var x = document.getElementById('feeds');
var containers = [];
if(x){
var links = x.getElementsByTagName('a');
var resources = [];
var urls = [];
for(var i=0,j=links.length;i'+items[i].title+'';
if(items[i].thumbnail || items[i].content){
var thumb = items[i].thumbnail || items[i].content.thumbnail;
out += ' ';
} else {
if(items[i].description.indexOf('src')!=-1){
var thumb = items[i].description.split('src="')[1];
thumb = thumb.split('"')[0];
out += '
';
} else {
if(items[i].description.indexOf('src')!=-1){
var thumb = items[i].description.split('src="')[1];
thumb = thumb.split('"')[0];
out += ' ';
}
}
out += '';
if((items[i+1] && items[i+1].link.substr(0,20) !=
items[i].link.substr(0,20))){
containers[c].innerHTML+='';
c++;
out='';
}
}
containers[c].innerHTML+='';
}
';
}
}
out += '';
if((items[i+1] && items[i+1].link.substr(0,20) !=
items[i].link.substr(0,20))){
containers[c].innerHTML+='';
c++;
out='';
}
}
containers[c].innerHTML+='';
}
However, the bad news about this is that it is pretty pointless as the performance is terrible. Not really surprising if you see what the YQL servers have to do and how much data gets loaded and analysed.
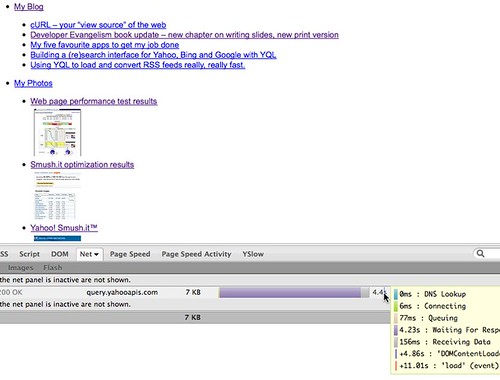
You could of course cache the result locally and thus get it down to a very small amount. However, if you go this way you might as well go fully server-side.
I am currently working on making icant.co.uk perform much faster, so watch this space for a generic RSS displayer :)
{kind=link}