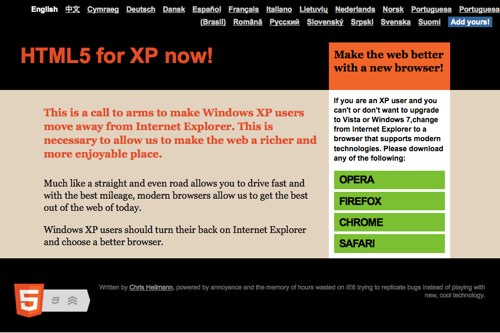
So what is this about? Well, frankly the thing that holds us back when it comes to developing a beautiful and simple to maintain and create web: Internet Explorer not getting upgraded.
Internet Explorer 9 is not available for XP users – you need to have Vista or Seven to get IE9
Upgrading to Vista was not really exciting enough for a lot of businesses when it came out
Upgrading to Seven normally means that you also need to upgrade the hardware (which is actually a very common happening – as a lot of users simply don’t know what a browser is or don’t get the rights to choose an own browser in a corporate environment IE only gets upgraded when they get a new computer)
A lot of Windows XP machines never got upgraded as they had a pirated OS. The Genuine Check of Vista told users “computer says no” and that was that.
Now, I personally want to have HTML5 and CSS3 and other new exciting technologies right now – I am tired of writing code for cool things that browsers should be doing for me.
As Microsoft is spending a lot of time and effort to promote just how cool IE9 is and glosses over the fact that XP users cannot get it, I thought it is time to advertise the fact that users have a choice – even when they stick with XP. For Microsoft this doesn’t make any business sense as they want to sell Seven, and they are right in telling people that systems need upgrades. However, if the upgrade means spending a lot of money on new hard and software then I can also understand people who don’t want to do that. With Apple products being very expensive and Linux just not being as “mom and dad end user friendly” as Windows is this is what we are stuck with.
This is why I built HTML5 for XP, the site that Microsoft should release themselves. Please tell people about it and send it to your clients.
Creating it was the fun part. I wrote it, created a simple web site (fighting the urge to use all kind of CSS3 awesome as it needs to work in IE6…) and then asked for translations and promotion on Twitter. I put up a Google Spreadsheet with the texts for translation and shared it with the world. This was a too hippy an idea as it meant people did the cool h4xx0rrrr! thing of deleting all the content (well done, lads, wait for Trinity to knock on your door really soon). So I made it an invite only document to submit translations and within a day I had 16 languages – now we are up to 20. I also have to thank Prisca for making the CSS pretty as of course the first feedback from designers was that “this is ugly”.
The saga continues – IE6 has to die! Spread the word.
I just returned from Confoo in Montreal, Canada where I gave a closing talk on the second day about innovating on the web using HTML5. Here are the slides, notes and an audio recording of the talk.
Slides
Audio recording
Notes
Today, we’ll talk about HTML5 - moving from hacks to solutions. This is a topic that I’ve covered a lot lately but funnily enough – I am not getting tired of it.
We work in new media!
The reason is that I’ve seen the worst of the web and I see HTML5 as a chance to make us move forward in our evolution of the internet as the media that works, is available for everyone and makes us more efficient rather than turning us into couch potatoes and forget our day to day worries in exchange to watching artificial people live the life we would love to have.
Oh, Canada!
First of all, it is good to be back in Canada – I like Canada a lot, Wolverine is from here and all the people I met so far in our small world are amazingly crafty developers.
HTML5 is tech evolution in action
So what is all that HTML5 stuff about? To me, it is about moving forward and letting go of ideas we consider to be the best solution but really only use because we are familiar with them. Better the devil you know, right?
A much more flexible internet experience
I think as developers we owe it to the world to build a better internet experience. Computers are very versatile things and connectivity allows us to keep things up-to-date, react to change and access systems on-demand rather than having all of them hoarded somewhere.
When did we stop dreaming of awesome computers?
If you look at the movies of the last few decades you will find that we more and more moved away from computers of awesome that react to voice recognition and have unlimited potential to product placements of the currently newest smartphone or system. The same seems to happen to the web – a lot of people already see the web as boring interlinked texts and web sites that don’t help you fulfil a task. Instead people see small apps for smartphones, tablets and other mobile systems as the future. I think the web as a concept is big and clever enough to allow for both.
Uprading is a good thing
Not many people complain when they get upgrades in real life. A better seat on the plane is a nice thing to have. A faster computer makes you work better as you don’t have to wait for the bloody thing to load and finish the tasks you have to achieve using it.
Staying in the comfort zone
When it comes to web technology though, you find a lot of people who are unhappy about change and don’t trust HTML5 and related technologies yet. Change can be a scary thing – especially when you’ve been disappointed in the past. It is tricky to trust browsers to do things right for us and it is very tempting to stick with what we know and say this is all we have – this is how good the web can be.
Still waiting for the closed technology revolution
Over my career I’ve seen many attempts to make the web a better and richer experience. A lot of plugins came and went. Java applets, VRML, Real Player, Quicktime, iPix, Shockwave and many more promised to make a browser more interesting and a richer experience. Flash and with it Air and Flex went furthest out with it and their success and adoption rate shows that we need a richer web. However, pure Flash solutions are still a rarity on the web. When it comes to complex forms, huge data systems and web based applications you are more likely to find hybrids or slow and annoying server-driven systems than slick Flash interfaces.
Starting the open technology revolution
The great thing about HTML5 as an idea is that we don’t ask people to buy software or understand and start to trust new technology – instead we innovate on already existing necessary infrastructure. You use a browser to surf the web – all we have to make people do is upgrade their browser. And as everything is open there is no ambiguity as to where things are going in the future – instead of making people wait for upgrades their requests and needs drive them.
A few steps towards a better web
We have the technology and we have the ideas to make the web much, much better. What we need to do is think the right way.
Step one: stop thinking in limits
If we want the web as it is now – easy to access, open for everyone and simple to upgrade – to survive we have to stop thinking in a limited way. Web sites do not have to be multiple columns of text or follow the same principles as print design does (plain psychology and aesthetics for humans are a barrier to this, but shift can happen). Web sites can be applications that break the concept of a text document. Web sites can be independent of the size of the browser viewport – either by adapting and showing more or less according to how much space is available or by just telling the user they can move in any direction.
Step two: use what the client offers
It is time we thank the browser vendors for supporting new technologies by using them. We’re right now in a Catch-22 situation were some people want browsers to support tech but the companies making browsers don’t add them yet as there is no demand. Time to break this cycle. Go on then, use local storage to make your interfaces much simpler by storing some of the information. Take a look at offline storage – not only for mobile interfaces. Play with geolocation to tell a user where they are or to prefill forms. Use native video and audio instead of yet another Flash movie. Use Canvas and SVG for charting and a fallback image linking to a browser upgrade page. Play with touch events and even with device orientation. A lot more than you think is already possible and can be used once you put it in a simple if statement.
Step three: increase your vocabulary
Communication is about vocabulary. Sure, you can make sense with a few simple words and a set of simple instructions but to make a sentence engage and spark the theatre in the head of the reader or listener you need to be able to play with language and the more pieces you have the nicer the mosaic will get. On the web we right now grunt and point when it comes to speaking to browsers. The old HTML vocabulary has become an anachronism hailing back to the times where all we had to do is mark up academic papers. Forms especially were too simple in what we needed to do with them to build enjoyable interfaces. In order to make the browsers do the things our apps natively should do we need more, intelligent HTML elements. The HTML5 spec is a step in the right direction, and we should use these wonderful new constructs to tell a better story. Non-meaningful DIVs should be replaced with SECTION, ASIDE or ARTICLE, form elements should not be a type of text but a phone number, a URL, a number or even an email. All of these words are at our disposal, but we don’t use them in day to day conversation yet which is why there is not much happening in terms of support. We should not be the translator for HTML to the browser – this can only lead to telephone-esque misunderstandings.
Step four: allow technology to retire
This is a tricky topic right now. A lot of HTML5 is not being used as there are old and outdated browsers still in use and for reasons beyond our control are not being upgraded. Here’s an idea: let’s allow old and tired browsers to retire. Let’s give them a working version of our web site that is plain HTML with reloads and the content available and let’s concentrate our efforts in supporting the web that is around the corner and needs us to become mainstream. Yes, we can simulate almost all of the new things in HTML5 for legacy browsers, but if we do that we also need to test on them to see that everything works smoothly. We should not spend our time testing for old browsers when there is new stuff to be tested. There is nothing wrong with delivering an old school experience to old technology and increase the enjoyment when and if the environment allows for it.
Step five: build systems that automate annoying tasks
Of course there are some annoyances in HTML5 - it is a young technology. The biggest issues however are not technical issues but licensing and IP related problems. For example to embed a video as HTML5 you have to provide it in three different formats to cover all browsers. That’s why we need to make it easy for people to make the switch. Vid.ly for example is a service that converts videos in dozens of formats and redirects the client in use to the correct format automatically. This is what we should thrive for – find issues and build systems to work around them – this is how money is made.
Step six: build tools that help others build with new technology
We have specs for the technologies and examples how to use them. We can, however, not expect everybody to be as excited about the things we are getting high on right now. We can also not expect everybody who builds things for the web or writes content for it to write everything by hand. The editors we use right now do not create HTML5 - most actually create XHTML instead. We now need to ask the companies who say HTML5 is the future to build systems that allow maintainers of the web to build it. One cool example of that is Butter which is a visual interface on top of the Popcorn JavaScript framework that allows you to build interactive presentations with HTML5 video. Aviary have an online image editor that uses HTML5 and the Aloha Editor is an HTML5 wysiwyg editor for CMS. We need more of that.
Step seven: be part of the discussion
Last but not least we need you to take part in the conversation around HTML5. If you stay out of it, you can’t complain about mistakes being made – all the processes are open and you can be part of the mailing list. It is not a popularity contents – sure, known people working in big companies are very likely to come up with good ideas, but anyone can have those and sometimes it is important not to look at an issue from a professional day-to-day perspective but see what people really need to have fixed. We need you to listen to what people are saying and validate it from your point of view. The earlier mistakes can be spotted, the easier they are to avoid. As we are dealing with open technology, there are no secrets and there shouldn’t be a reason for people not answering your questions. It is also important to look out for upcoming problems that are not yet in the specifications. Right now for example this would be the device API which will allow you to use cameras and microphones as input devices.
Last week Microsoft released ie6countdown.com, urging developers to tell their IE6 visitors to upgrade their browsers to a newer browser to have a better experience on the web. Thumbs up for that – we need to get that message out to people (after all this is what the WaSP has done years ago with their “To hell with bad browsers” campaign years ago to make people upgrade from Netscape 4 and IE4).
Alas, the implementation of the “nag bar” is riddled with mistakes. They’ve done the right thing in wrapping the code in a conditional comment (a technology that is still Microsoft’s finest moment in web development when it comes to IE) but there are many issues with it (as also pointed out by Steve Webster, Mike Davies and Bruce Lawson):
The nag bar is an image without any alternative text – which means no blind user will ever know why there is an image there and not get the upgrade message – and a lot of people are stuck with IE6 when they use old screenreaders. Why not a styled DIV? Even IE6 knows style sheets!
All users get sent to the IE download page to upgrade which means XP users get asked to download IE8 – and this browser is not much better, really, as explained in detail by Alex Russel.
Telling people to upgrade IE6 is pointless if the systems they have to use don’t work on other browsers – granted, Microsoft jumps through hoops with every release of IE to be backwards compatible, but some things simply are that badly developed that they don’t work on new browsers. The irony is that a lot of these systems are based on Microsoft’s frameworks and CMS or even “best practice documentation” that was hot at the time it came out but makes you facepalm when you read it these days.
Microsoft painted themselves into a corner years ago when they made the browser dependent on the operating system. Yes, this yields better results as you control the environment (a tempting situation to be in which is why Apple now does exactly the same with Safari and Mobile Safari) but it also means that your browser is much harder to keep up-to-date when there is no incentive to upgrade the operating system. And this is where the main issue lies with Internet Explorer upgrades:
Windows Vista was not good enough to upgrade from XP and Windows 7 does not run on old hardware.
And as Windows users upgrade their browsers with their operating system this means we are still stuck with IE6 or – in a best case scenario – IE8. That is not the Internet I want to have, sorry! Our clients and end users deserve better!
You may say that upgrading is easy and hardware gets cheaper every year but the issue is that the places where IE6 still reigns supreme are those places where a hardware upgrade means replacing thousands of machines and is connected with a four month security and compliance audit. In the current financial climate a lot of large companies, government agencies and academia simply see upgrading hardware as a luxury. And this is where Microsoft should finally own up and grow a pair.
Some ideas of what Microsoft could do to really help solving the Internet Explorer upgrade problem.
Microsoft needs to stop pretending that there is no competition – right now Opera, Chrome and Firefox are the only sensible upgrades for Windows XP users – even offering hardware acceleration. Google have no problem pointing out other browsers when it comes to upgrading and leave the choice to the user. This is where the upgrade message should point to.
Microsoft could patch IE8 to support new features – something Chrome Frame tries to do – you can not expect people to upgrade their hardware to get a new browser – unless you give them a helping hand.
Microsoft should offer a financial incentive to upgrade systems – people upgrading whole systems from a locked-in IE6 infrastructure should get subsidised hardware and very good licensing packages. Google released their free laptop programme for people to give their new OS a go – this could be done by Microsoft, too.
Microsoft should offer free training and consulting on how to upgrade – again, instead of wasting money on marketing stunts for IE9 guide people to the changes that need to happen. IE6 is a security risk and keeps us from making products that are fun to use and fulfil a task.
Microsoft could open source IE – both Chrome and Firefox innovate and get constantly patched and improved by communities outside of the main development team – if we could fix things in IE, we would!
Microsoft should kill old IE – well, more like euthanise it. It has done its duty and has the right to retire. It is not enough to say “upgrade” – remove all downloads, don’t offer patches, remove all the documentation about IE6 only features. Instead of creating a marketing site and ask the community to spread the word start on your own doorstep. Send out newsletters to the MSDN community and say on your conferences that IE6 is End Of Life and support requests are not answered any more.
IE6 must die! Let’s make it happen. Please, Microsoft?
I just got roped in by my colleagues here to tell you about another cool job opportunity at Mozilla:
Tech Evangelist – Jetpack
Jetpack is a Mozilla project whose mission is to make it easy to build Firefox add-ons using common web technologies like HTML, JavaScript, and CSS.
As Tech Evangelist for the Jetpack project, your job is to lead the effort to build a rich ecosystem of add-ons and APIs by telling the world about our awesome technology; mentoring project participants who interact with add-on and API developers; and channeling feedback from developers into the project planning process.
You see the big picture, and you get other people to see it too.
You make add-on development great!
Responsibilities
develop, distribute, and conduct videos, blog posts, presentations, tweets, tutorials, example add-ons, and other informational and educational materials about project tools and technologies
lead Mozilla’s Add-on Ambassadors program and mentor project participants in technology evangelism principles and practices
assist the product manager in determining developer needs and setting project goals and priorities
Requirements
at least five years experience in the software industry as a tech evangelist, community manager, product/project/program manager, technical lead, software engineer, or in another related position
exceptional written and verbal communications skills, including the ability to communicate with add-on developers, API developers, journalists, business types, and various other folks on their own terms and at their own level of technical knowledge and understanding
a strong desire to make add-on and API development great
Desirements
a BS degree in computer science or a related field
experience evangelizing, managing, designing, or developing software products for developers, especially software development kits and API libraries
experience managing, designing, or developing modern web sites and applications
experience working in and with open source projects
experience working for non-profits or other kinds of mission-driven organizations
I just marked up and released a paper that was rejected for a conference I applied to about using the social web for development: http://icant.co.uk/social-development/. It describes how developers can use the power of the social web to advertise, improve and even develop their products.
The article is licensed with Creative Commons, so feel free to use it in your own products. And if you want me to deliver it as a talk at your conference, why not drop me a line on Twitter? :)
This also taught me not to bother at all with conferences any longer who ask you for a full paper as a submission, especially when they are academic conferences. The reviews I got for this were quite harsh and missed the point that I was trying to make that we are treading new ground here and there is no way to build on earlier successes or quote case studies.
I hope it is useful to you, and I’d love to get some feedback.