
Humans are a weird bunch. One of our great traits is that when someone tells us that a certain thing is a certain way, we question it. We like debating and we revel in it. The more technical you are, the more you enjoy this. As someone once put it:
Arguing with an engineer is like wrestling with a pig in shit. You realise far too late that it enjoys it.
Now, the web as we have it these days isn’t in a good place.
- It is slow, full of unwanted content
- It allows others to track our users without our knowledge
- It is full of security holes and much less maintained than it should be to prevent them becoming an attack vector
- It lacks support for physical and digital availability for all.
- Developers get very simple things wrong and often a mistake is copied and pasted or installed over and over
That means that browsers, which by definition can not break the web, need to be lenient with developer mistakes. All browsers fix a lot of problems automatically and allow for spelling mistakes like “utf8” instead of “UTF-8”. That also makes them bigger, slower and harder to maintain. Which makes us complain about browsers being just that.
It can’t be a problem of lacking resources
Considering how much free, high-quality information we have available this is weird. We have web documentation maintained by all the big players. We have up-to-date information on what browsers can do. We drown in conferences, meetups and we don’t even need to attend them. Often talk videos pop up on YouTube within minutes after the presenter left the stage.
We also have excellent tooling. Browsers have developer tools built in. Editors are free, some even open source and we can configure them to our needs using the languages we use them to write. We have automated testing and auditing tools telling us what to optimise before we release our products.
Maybe it all is too much to take in
The problem seems to be overload. Both of options and especially of opinions. We can’t assume that every web developer out there can go to conferences, follow blog posts and watch videos. We can’t assume that people can deal with the speed of news where a “modern, tiny solution” can turn into a “considered harmful” within a day. We also can’t assume that what is a best practice for a huge web product applies to all smaller ones. Far too often we’ve seen “best practices” come and go and what was a “quick, opinionated way to achieve more by writing less” turned into a stumbling block of the current web. Even more worrying, when a huge successful corporation states that something works for them developers are asked to use these settings and ideas. Even when they don’t apply to their products at all.
There is no one-size-fits-all best practice
The web is incredibly diverse and the same rules don’t apply to everything. We are very quick to point the finger at a glaring problem of a web product but we don’t ask why it happened. Often it is not the fault of the developers, or lack of knowledge. It is a design decision that may even have a sensible reason.
We faced the same issues at my work. Working in a large corporation means many chefs spoiling the broth. It also means that different projects need different approaches. I am happy to give Internet Explorer users a plain HTML page with a bit of CSS and enhance for more capable environments. But not everybody has that freedom – for them a high-quality experience on that browser is the main goal. Everything else isn’t part of the product time buffer and needs to be added on the sly. Different needs for different projects.
Damage control
That said, we didn’t want to allow low-quality products to get out of the door. Often us in the inner circle of the “modern web” preach about best practices. Then some marketing web site by your company makes you look silly because it violates them. We needed a way to evaluate the quality of a project and get a report out of it. We also needed explanations why some of the problems we have with the product are real issues. And we needed documentation explaining how to fix these issues.
This is when we created a product that does all that. It is a scanner that loads a URL and tests all kind of things it returns. It uses third party tools to test for security and accessibility issues and is available open source on GitHub. As we don’t want this to be just a thing of my company, we donated the code to the JS foundation.
At first, we called the product Sonar. That was a copyright issue. So we renamed it to Sonarwhal. It had some success, and then more naming clashing issues cropped up. Furthermore, people didn’t seem to get it.
Today, we released a new, rebranded version of the tool. It is now called Webhint and you can find it on GitHub, use it at webhint.io or use it as a node module using npm, yarn or whatever other package installer you want to use.
The simplest use case is this:
- Go to webhint.io Enter the URL you want to test
- Wait a bit till all the hints came back
- Get a report explaining all the things that are sub-optimal to dangerous. You don’t only get the error messages, but detailed explanation what these mean and how to fix the issues.
By default webhint tests for these features of great web products: Performance, Accessibility, Browser Interoperability, Security, Sensible configuration of build tools and PWA Readiness.
Make up your own tests checking what matters to your product
Whilst this is great, it doesn’t solve all the issues we listed earlier. It is a great testing tool, but it has its own opinions and you can’t change them.
- What if your tool doesn’t need to be PWA ready?
- What if performance is less of an issue as you run on an intranet behind a firewall?
- What if you can’t access webhint.io as you are working in a closed network?
- What if you don’t use a browser at all but you also want to test a lot of documents for these quality features?
This is where the node version of webhint comes in. You can get it and install it with npm (and others, of course). The package name is hint .
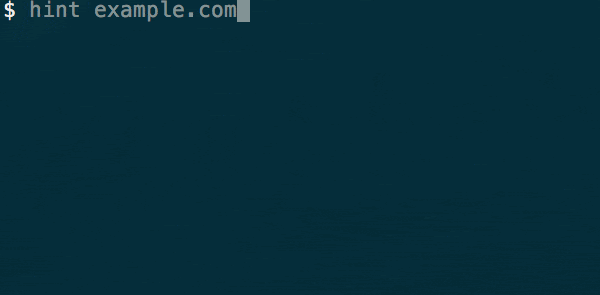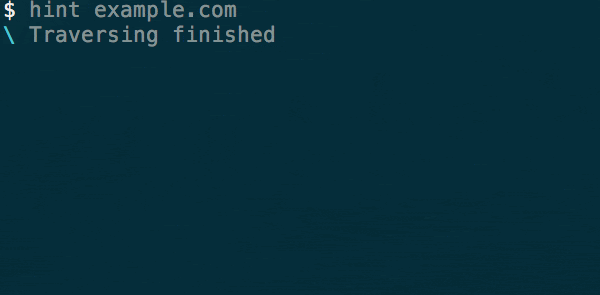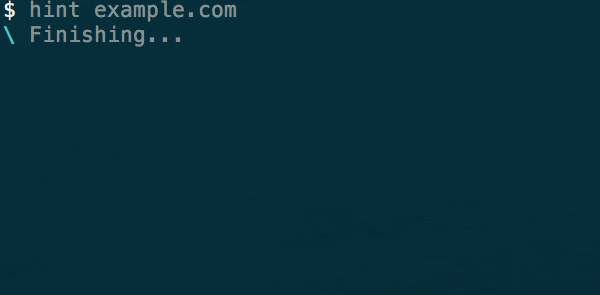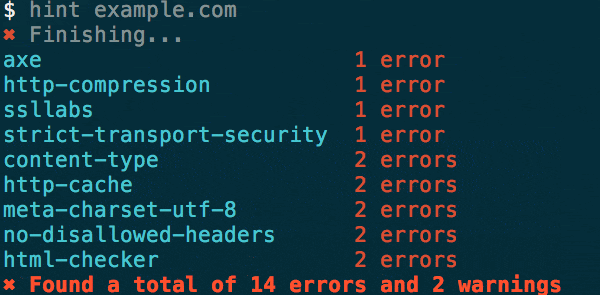
That way you can not only scan a URL from the command line, but you can also configure it to your needs. You can define your own hints to test against and turn the out-of-the-box ones on and off. You can turn off the ones reliant on third party scanners. You can even have different configurations for each project.
With the release today of webhint, we took what was Sonarwhal and made it faster, smaller and easier to use. The command line version now has a default setting and adding and removing hints is a lot easier. The startup time and the size of webhint is much smaller and things should be much smoother.
So go and read up on the official release of Webhint, dive into the documentation or just do some trial scans. You’ll be surprised how many things you find that can have a huge problematic impact but are relatively easy to fix.
I hope that a tool like webhint, without fixed opinions and customisable to many different needs whilst still creating readable and understandable reports can help us make a better web. Watch this space, there is a lot more to come.
