That was my Beyond Tellerrand Munich 2018 – Keynote talk/slides and impressions
Friday, January 19th, 2018I just got back from Beyond Tellerrand in Munich and here’s a quick report what you missed if you didn’t go. You might not be interested in my impressions, so let’s get my work out of the way first.
I gave the opening keynote “Sacrificing the golden calf of coding” in which I explained my transition from a hobby coder to a professional developer and learning along the way that tooling and automation is not the enemy.
The video is already available on the Vimeo Channel:
Sacrificing the golden calf of “coding” – Christian Heilmann – btconfMUC2018 from beyond tellerrand on Vimeo.
I also added the slides to Slideshare:
As you may know, I am a huge fan of Beyond Tellerrand. The organizer is a very old friend of mine and he bends over backwards to make the event something special. He cherry-picks the speakers, treats them immensely well and on a deeply personal level. I feel very proud to be a part of this for many years. On a personal level, I am chuffed about its success as my partner and me met at this event. Thus, she also was a volunteer this time and helped making this event work smoothly for all the attendees.

I was worried that branching out from Duesseldorf to Berlin and Munich might be a tough step for the event and as Munich is not a hotspot for events I worried about participation numbers. But I shouldn’t have. The even was full up and people stayed for the whole duration. I was heartbroken to hear about a massive personal loss in the organiser’s life just before the event and I am even more so impressed how well it worked out.

I shot quite a few photos at the event, none of which of course will match what the official photographers managed to get.

Beyond Tellerrand is ridiculously fast in releasing the videos of the event as they are mixed live. I love this as with booth duties at the Microsoft stand and personal errands I couldn’t see all the talks but will do so now in the nearer future. Here are some picks that may tickle your fancy, too:
Simon Collison’s “The Internet of Natural Things” talk was a lovely reminder how the internet is not all about cold technical things but also a way to organise your life and record natural things around you. It ends with an intriguing new way how an OS could look to be more helpful for people in their natural environment.
The Internet of Natural Things – Simon Collison – btconfMUC2018 from beyond tellerrand on Vimeo.
Harry Robert’s “Why Fast Matters” is a talk full of great information on how to measure and improve the speed of your products and what the positive effects of that can be. Harry does not only show tools but also proves why considering improvements can make profound business sense. And he explains how well performing products are truly international and help you reach new markets without breaking the bank of users who live there. His slides with all the links are available on speakerdeck.
Why Fast Matters – Harry Roberts – btconfMUC2018 from beyond tellerrand on Vimeo.
Nadieh Bremer’s “Data Sketches: A Year of Exotic Data Visualisations” is a whirlwind explanation of her last year of creating bafflingly beautiful data visualisations. She doesn’t only show off her work and talks about the beauty of it but explains the story warts and all – from having to scrape and clean up the data to iteratively doing the math on paper to get the effects she wanted to have.
Data Sketches: A Year of Exotic Data Visualisations – Nadieh Bremer – btconfMUC2018 from beyond tellerrand on Vimeo.
Dina Amin’s “A tinker story” was a total surprise to me and clearly the winner of the event. It already inspired me to write two new talks. Dina is a lady from Egypt who likes to take mechanical things apart and build stop motion animations from them. That’s impressive enough, but the real beauty of the talk is about her story. How she dared to do something that crazy and creative instead of pursuing a normal career and how the internet and working with other people over it made that possible. If you want to see some really cool animations and hear a story of empowerment and joy, this is for you.
A Tinker Story – dina Amin – btconfMUC2018 from beyond tellerrand on Vimeo.
Make sure to keep checking the channel for more videos coming up. Another absolute highlight was Stefan Sagmeister’s closing keynote which was a gorgeous and sweary rant about how we should embrace beauty instead of following outdated Bauhaus ideas. And it ended with the whole audience singing along with him to a song about beauty.

There is no question in my book that Beyond Tellerrand is a worth-while conference to support and attend. My company agreed to support all the events this year and I am looking forward to seeing the next one in May in Duesseldorf. You should, too.
We’re not giving browsers enough credit…
Thursday, January 4th, 2018I’m currently working on a few projects that are special browsers. I can’t put in any more details but the gist is that I will only have a WebView to play with. The interface of the browser is JavaScript/CSS/HTML, for which we use vue.js and Sass respectively.
I am also running an insider build of the OS as I want to be on the bleeding edge. My own browsers is a developer preview. This all taught me quite a few things.
- There is a huge difference between a browser and a webview
- It is possible to build all kind of fancy interfaces in web technologies. But often there are hard to work around security, performance and accessibility issues.
- Day-to-day browsing sucks when your browser is a moving target
The main thing it taught me that as developers, we have a massively skewed view of what a browser is. Or, more accurately, what matters to users.
A browser is a web display tool
Photo by Kevin KuIn my meetings with clients, I found a few things that mattered most to them:
- Performance – a browser should start up fast, not bog down the operating system eating resources and stay responsive. This is not only about first use, but often a big need for long-term use – for example in a kiosk scenario. Browser restarts are uncommon and should not be necessary
- A reliable content display – a browser should also render content instantly. Content could be HTML documents with all the cruft they come with these days. But it is increasingly important that media of all kind plays smoothly. And often there is no chance to rely on a plugin or third-party player. This means a browser should be a video/audio player. It also should be an ePub and PDF reader. And it needs to render huge images and WebGL/WebVR content without any hiccups.
Neither of those should come as a surprise – this is also what we as developers expect. As developers we also want more. We put a lot of stake into the developer tools experience. And we want browsers to support the newest and hottest experimental technology. And we complain to other browser makers if not all are on par with the others on both these counts.
Most clients that wanted a bespoke browser, however, had other priorities.
A browser is an enabler
Photo by rebeck96I was happy to hear that every customer I worked with put a high emphasis on accessibility. I was less happy to see how tough it still can be to make a zoomable interface in a WebView. And how to get keyboard access right. And how to enable screenreader access and text to speech interfaces. But that’s my job as a developer. And yours, too.
A browser needs to enable people of all different abilities to reach what they came for. And ability isn’t a fixed state but fluctuates with environment and external influences. I found that out lately when I had to zoom my browser to 110% to read the average web site. A reminder that I am the age I look. I fixed it later by switching to varifocals, but I am happy that browsers allow me to fix it on the spot. Often a WebView embedded in an App doesn’t allow that.
A browser is a guardian
Photo by ShonEjaiA very common demand is to have blocking of unwanted content in the browser. This ranges from must haves like malicious site filters to popup blocking up to providing a pre-approved whitelist and block all else. Ad-blocking is also often a demand, but the big worry is that an opened document could give an attacker access to the computer.
Browser creators have a shared list of known attack sites to filter out. This is a great service that protected quite a few people over the last years.
Displaying insecure content in a secure site is another problem that I needed to work with. Whilst browsers have UI interfaces and blocking built-in some WebViews allow mixed content. That’s not good.
People also wanted to ensure that there is no dependency on plugins for video display or to outright ban Flash content. PDF was a big concern, too. And they were right to do so. Browsers do a lot to avoid malformed PDFs to spy on us.
Speaking of spying, a private browsing mode or a general browsing experience that blocks trackers was also high on the list. This is not surprising and a sensible feature to offer.
The opposite of a private mode is, however, also something that we keep underestimating.
A browser is a memory keeper
Photo by Rachel DemsickBrowsers are there for us to display the web, but they are much more importantly there to make this easier for us the more we use them. I felt that in my own use of an unreliable (preview) browser in a constantly changing configuration. I realised just how much it sucks having to constantly re-enter passwords. How annoying it is not to have sites I keep visiting autocomplete when I type a few letters of the URL. How “share with X” buttons become useless when you are not logged in. In essence, how much I rely on the browser to remember what I’ve done and intelligently help me along the way.
We don’t give browser makers enough credit for this amazing experience, as it is – like all good UX - invisible. A browser that automatically and safely stores and enters form data for me is a great help. It even protects me from entering wrong information and the frustrating re-filling experience. Yes, of course this is also an attack vector, but that doesn’t mean we shouldn’t celebrate its usefulness – we should make it more secure instead.
Having Firefox’s “awesomebar” remember my surfing habits over the last 10 years spoiled me. I don’t even remember the last time I bookmarked anything. My important finds I tweeted out anyway and let Pinboard remember them for me.
Others may as well have a lot of bookmarks. Together with synced autofill content and history it is great to be able to take this experience with you. Independent of computer, phone or device.
Conclusion
When it comes to answering what a browser does for us, I learned a lot in the last few months. I am more humble when demanding features of my colleagues and friends in other companies working on browsers. They are doing an incredible job building a piece of software that displays the web in an accessible and secure way. And once you learn about attack vectors of the web and webviews you are in for some rough nights.
I also learned that when it comes to who wins the most users in the browser space, it comes down to how they handle user data. Technical ability of a platform and “pushing the envelope of what the web can do” is exciting for us as developers. End users, however want the web to be easy, fast and secure to use. They also want their browser to know where they’ve been, and choose when it shouldn’t. They want a few things automated and get easy access to their content to send out to the web. From a privacy point of view, I also feel uneasy about this, but those who make this the easiest, win.
When it comes to what browsers can do, they’re much more on par than they’ve ever been – thanks to standards. The big differentiator isn’t what tech to support, it is how much of a travel companion on the web the browser is. It is a game of data, insights and good UX of the browser interface itself.
I am much more excited about what we can do in the future to help people keep their online identity in a browser without leaking it. And I would love to see more interfaces that teach people the value of their own data whilst using a browser.
A browser is not merely a display mechanism for the web. It is a record of your identity and history on it. This can be a great thing if done well, or a scary one if not. I’m worried that too many people on the web leave breadcrumbs without knowing it. They see the convenience of that without knowing the consequences or value to others.
I invite any other web developer to look closer at the interface elements and user-centric features of browsers. There is a lot of beauty and very clever, researched-based interfaces to be found. And I’d love to see this get more coverage in our circles, and not only which new API or tech feature is the next big thing.
The web we may have lost
Sunday, December 17th, 2017The current blow to the open web that is the Net Neutrality ruling feels terrible to me. My generation saw the web emerge and many of us owe our careers to it.
There are a few reasons why the ruling is terrible. First of all are the things that everybody should worry about. Allowing ISPs to favour some traffic over others turns the web into a media of the elite. Mozilla’s Mitchell Baker explained this in detail in her CNN opinion piece. The other reason is that a web controlled by ISPs stifles innovation and opens a floodgate for surveillance as explained in this excellent Twitter thread by @jtm_.
I am not surprised that it came to this. The world-wide-web always scared the hell out of those who want to control what people consume and what their career is. The web was the equaliser.
Anyone can publish, anyone can consume and learn. And there was no way to protect your content. People could download, share and remix. From a pure capitalist point of view this is anarchy. From a creativity point of view, it is heaven.
Before we had the web all the information you wanted to access meant you either had to pay or you had to put a lot of effort in. I remember in school cycling to the library and lending out books, CDs and later DVDs. I also remember that I had to be on time or the thing I wanted to research wasn’t available. I didn’t have the money to buy books. But I was hungry to learn and I love reading.
When I got access to the web this all changed. My whole career started when I got online and I taught myself to start writing code for the web. I never finished any job education other than a course on radio journalism. I never went to college as we couldn’t afford it.
I went online. I found things to learn and I found mistakes I could help fix. I was online very early on when the web was, well – shit. I wasn’t tempted by thousands of streaming services giving me things to consume. Even downloading an MP3 was pretty much wishful thinking on a dial-up connection that cost per minute. I used the web as a read and write medium. I wrote things offline, dialled up, uploaded my changes, got my emails and disconnected.
As a kid I would ask my parents to stop at motorway gas stations to see trucks and cars from other countries. We didn’t have much money for holidays, so any time I could meet people outside my country was a thrill for me. You can’t imagine the thrill I felt when I had my first emails from people from all over the world thanking me for my efforts.
Using the web, I could publish world-wide, 24/7 and could access information as it happened.
This was a huge change to going to the library or reading newspapers. A lot of the information I gathered that way was outdated before it even got published. Editing and releasing is a lengthy process. There’s a flipside, of course. Materials published in a slower, more editorial process tend to be of higher quality. I learned that when I published my books. I learned that having a daunting technical editor and a more formal publishing format pushed me to do better. A lot of what I had blogged about turned out to be not as hot as I thought it was when I re-hashed it in book form.
That’s the price to pay for an open publishing platform — it is up to the readers and consumers to criticise and keep the publishers in check. Just because it is online doesn’t mean you should trust it. But as it is online and you can publish, too, you can make it better.
One great thing about an open web was that it enabled me to read several publications and compare them. I didn’t have to buy dozens of newspapers and check how they covered the same topic. I opened them one after the other and did my comparison online. I even got access to the source materials in news organisations. I had quite a chuckle seeing how a DPA or Reuters article ended up in other publications. A web without Net Neutrality wouldn’t allow for that. I’d be fed the message of the publisher that paid the most to the ISP. That’s shit. I might as well watch TV.
I spent 20 years of my career working on and for the web. I did that because when I started it was a pain in the backside to get online. I felt the pain and I very much enjoyed the gain. I had to show a lot of patience geting the content I wanted and publishing my work.
I didn’t have much money from my job as a radio journalist. I took a 10 pack of floppy disks with me to work (later on I used DVD-RWs and re-wrote them). I downloaded whole web sites and articles at work and read them offline at home. I still have a few CDs with “Photoshop tutorials” and “HTML tricks” from back then. Offline browser tools like HTTrack Website Copier or Black Widow were my friends.
At home, I didn’t “surf” as we do now. I opened many browser windows, loaded all the sites and then disconnected. It was too expensive to be online. I would disconnect and go through the browser cache folder to save images that loaded instead of looking at them loading. Dial-up meant hat I paid the same for every minute online as I would have paid for calling someone.
I’ve always wanted to make this better. And I wanted to ensure that whoever wants to use the web to learn or to find a new job or make some money on the side can do it.
And this is where I am angry and disappointed that there is even a possibility that Net Neutrality is in danger.
There is a lot to hate about the “cool viral video” PSA from Chairman of the FCC Ajit Pai
It is smarmy, arrogant and holy crap is it trying to be trendy and cool. But what riled me most about it is that the FCC thinks the main points of worry when it comes to the users of the web are:
- Posting Pictures of food and animals
- Shopping
- Watching media-produced shows and movies
- Be a fan of the same
- Post Memes which are remixes of the same
And what scares me even more is the thought that they could be right. Maybe this debate now is a wake-up call for people to understand that the web is a voice for them. A place for them to be a publisher instead of a consumer or repeater of other content in exchange of social media likes and upvotes. It is time to fight for the web, once again.
I’ve always wanted to keep the big equaliser available for all. And I am excited to see what will come next. I look forward to see who will do amazing things with this gift to humanity that is an open publication platform. And how cool is it nowadays to have laptops and mobile phones to carry with you? You can sit in a cafe, access WiFi and you can be and do whatever you want. Wherever inspiration hits you or you try to find something out – go for it.
I sincerely hope that this is what the web still is. I understand that for people who grew up always online that the web is nothing special. It is there, it is like running water when you open a tap. You only care about the water when it doesn’t come.
And I hope that people still care that the web flows, no matter for whom or what the stream carries. The web did me a lot of good, and it can do so for many others. But it can’t do that if it turns into Cable TV. I’ve always seen the web as my media to control. To pick what I want to consume and question it by comparing it. A channel for me to publish and be scrutinised by others. A read-write medium. The only one we have. Let’s do more of the write part.
Web Truths: The web is world-wide and needs to be more inclusive
Wednesday, December 13th, 2017This is part of the web truths series of posts. A series where we look at true sounding statements that we keep using to have endless discussions instead of moving on. Today I want to talk about the notion of the web as being a world-wide publishing platform and having to support all environments no matter how basic.
The web is world-wide and needs to be more inclusiveWell, yes, sure, the world-wide-web is world-wide and anyone can be part of it. Hosting is not hard to find and creating a web site is pretty straight-forward, too.
Web content needs to be as inclusive as possible, that’s common sense. If we enable more people to access our content, there is a higher chance we create something that is worth while.
There is no question at all that web content should not exclude people because of their ability. As web content used to be text as a starting point this wasn’t extra effort. Alternative text for images, descriptions for complex visuals and transcripts for videos. These, together with assistive technology and translation services allowed for access. I won’t talk about accessibility here. This is about availability.
For those who started early on the web these are basic principles you need to follow when you want to play on the web. Which is why we always cry foul when someone violates them.
- When someone creates a product that only works in a certain market
- When something is only in one language or assumes people know how to work around that problem
- When a product assumes a certain setup, operating system or browser
- When a product relies on new technology without a fallback option for older browsers
These are all valid points and in a perfect world, they’d be a problem for a publisher not to follow. We don’t live in a perfect world though, and the sad fact is that the web we defend with these ideas never made it. It died much earlier when we forgot a basic principle of publication: how do you make money with it.
If all you want is to publish something on the web, and your reward is that it will be available for people you’re set. This attitude is either fierce altruism or stems from a position where you can afford to be generous.
For many, this isn’t what the web is about. Very early on the web was sold as a gold-mine. You create a web site and customers will come. Customers ready to pay for your services. Your web site is a 24/7 storefront that doesn’t have any overhead like a call centre would.
Amongst other problems, this marketing message lead to the mess that the web has become. It isn’t about making your content available. It is about reaching people ready to pay for your product or at least cover your costs. Those aren’t hypothetical users all over the world. For most companies that rely on making money these are affluent audiences where the company itself is. There are, of course, exceptions to this and some companies like the NYC based dating site Ignighter survived by realising their audience is coming from somewhere else. But these are scarce, and the safe bet or fast fail for most publishers was to reach people where they are.
You can’t make money if you spend too much, and thus you cut corners. Sure, it sounds interesting to have your product available world-wide. But it is more cost-efficient to stick to the markets you know and can bill people in. That’s why the world-wide-web we wanted to have is in essence a collection of smaller, local webs.
I’m moving from England to Germany. I’m amazed how many people use local web products instead of those I use. Some are because of their offers – the Netflix catalogue for example is much larger in the UK. But many are a success because of classic advertising on TV, in trains and newspapers.
As competiton grew it wasn’t about creating valuable content and maintaining it any longer. It was about adding what you offer and find shortcuts to get yourself found instead of your competition. And thus search engine optimisation came about and got funding and effort.
Of course it makes sense to have your product available in one form or another on all browsers and on enterprise and legacy environments. But is it worth the extra effort? It is when you start with your aim being publishing content. But many web products now don’t start with content, they start as a platform and get products added in a CMS. And that’s when browser market share is the measure, not supporting everybody. A browser that works well on Desktop and is also available on the high-end smartphones is what people optimise for. Because that’s what every sales person tells you is the target audience and they can show fancy numbers to prove that. That this seems short-sighted is understandable for us, but we also need to prove that it really is. In a measureable way with real numbers of how much people lost betting on one environment in the short term.
The sad fact we have to face now is that the web is not the main focus of people who want to offer content online any longer. Which seems strange, as apps are much harder to create and you are at the mercy of the store publishers.
Apple just announced that next year they disallow templated and generated apps. This is a blow to a lot of smaller publishers who bet on iOS as the main channel to paying customers. No worry, though, they can easily create a web site and turn it into a PWA, right?
Well, maybe. But there is an interesting statistic in the Apple article:
According to 2017 data from Flurry, mobile browser usage dropped from 20 percent in 2013 to just 8 percent in 2016, with the rest of our time spent in apps, for example. They are our doorway to the web and the way we interact with services.Of course, one stat can be debated, and the time we spend in apps doesn’t mean we also buy things in them or click on ads. A good web site may be used for 30 seconds and leave me a happy customer. However, new users are more likely to look for an app than enter or click a URL. The reason is that apps are advertised as more reliable and focused whereas the web is a mess.
On the surface for Apple, this isn’t about punishing smaller publishers. This is a move to clean up their store. A lot of these kind of apps are either low quality or meant to look like successful ones. Reminds us of the time when SEO efforts did exactly the same thing. Companies created dozens of sites that looked great. They had custom made content to attract Google to create inbound links to the site they got paid to promote.
The sad truth about the web and the fact that publishing is easy is that the cleaning step never happens. The best content hasn’t won on the web for years now. The most promoted, the one using the dirtiest tricks whilst skirting Google’s TOCs did.
A lot of what is web content now is too heavy and too demanding for people coming to the web. People on mobile devices with very limited data traffic at their disposal.
That’s no problem though, right? We can slim down the web and make it available to these new markets. There is no shortage of talks at the moment to reach the next billion users. By doing less, by using Service Workers to create offline ready functionality. By concentrating on what browsers can do for us instead of simulating it with frameworks.
Maybe this is the solution. But there is a problem that often we come from a position of privilege that is much further from the truth than we’d like to. Natalie Pistunovich has a great talk called Developing for the next Billion where she talks about her experiences releasing a product in Kenya, one of the big growth markets.
There is a lot of interesting information in there and some hard to swallow truths. One of them is that smartphones are not as available as we think they are – even low end Androids. And the second is that even when they are that people aren’t having reliable data connections. Instead of going to web sites people send apps to each other using Bluetooth. Or they offer and sell products on WhatsApp groups – as these tend to be exempt of the monthly data allowance. With Net Neutrality under attack in the US right now, this could be the same for us soon, too.
Of course these are extreme conditions. But the fact remains that closed systems like WhatsApp allow these people to sell online where the web failed. Not because of its nature and technologies, which are capable enough for that. But because of what it became over the years.
The web may be world-wide as a design idea, but the realities of connectivity and availability of web-ready hardware are a different story. Much like anything else, a few have both in abundance and squander it whilst others who could benefit the most don’t even know how to start.
That’s why the “reaching the next million users with bleeding edge web technology” messages ring hollow. And it doesn’t help to tell us over and over again that it could be different. We have to make it happen.
Skip to searchSo, you learned JavaScript – what now?
Tuesday, December 5th, 2017Yesterday, I was asked by the Berlin chapter of Women Techmakers to give a talk at the graduation ceremony of their JavaScript Crash Course. I wanted to give a talk about the next steps you can take now you learned the basics of JavaScript in 2017 instead of repeating old ideas. This is what I came up with.
First of all, congratulations – you chose wisely. JavaScript has evolved from being a “toy language”, “real programmers” laughed at into the language that powers the web and beyond.
For better or worse. JavaScript isn’t a perfect language- if something like that even exists. But it has a few things that speak for it.
JavaScript is everywhere
First of all, it is by now ubiquituous and you can create a lot of amazing things with it.
- You can use it in a browser environment to make web “things” that are highly interactive. These could be web sites that respond better and are more engaging when Javacript works. They could also be apps that users install and don’t even need to know that you used HTML. CSS and JavaScript to build them. They could even be complex games and VR experiences.
- You can also go server-side with Node. Then you can use JavaScript to build APIs, services and even full-fledged servers. You can create build processes and automate a lot of boring tasks that in the past needed a server to run on.
- You can use abstraction frameworks to publish on the web and create binary formats for iOS, Android and others. By starting with JavaScript, you can convert into many other things – something that isn’t sensibly possible the other way around.
- Or you can go completely wild and build robots that get their instructions in JavaScript. You can automate operating systems. You can write extensions for browsers and you can script other applications.
- You can publish to and take advantage of NPM, a vast resource of pre-build solutions you can mix and match to build your own – more complex – solutions. This is tempting, but there is also a danger of using too much and using things you don’t understand. So, whilst we’re in a package world with JavaScript, it makes sense to remember what JavaScript is and start there.
Mastering JavaScript isn’t easy, but getting started is simpler than with other languages. You are not dependent on a certain editor and you don’t need to compile it to create something that can run. Most important of all – you don’t need to spend any money to get started. Browsers are free. A lot of editors are free and many even open source. Above all, documentation is online and available to you.
You know the best thing though? I envy you!
I’ve been working with JavaScript more or less since it has been around and I’ve been carrying a lot of ballast with me.
There is a running joke where you can see the “Definitive Guide to JavaScript” book next to Douglas Crockford’s “JavaScript – the good parts”. The latter is much, much smaller. This doesn’t mean that JavaScript is bad. It means that the versatility of JavaScript can be its own undoing. JavaScript runs everywhere. Over the years terrible environments left a track record of awful APIs and methods. The standardisation process of JavaScript has been a roller-coaster ride. The Definitive Guide explains that. It is a compendium of all that happened – good and “dear me, why would you even consider doing this in JavaScript?”. The Good Parts book sticks to the syntax and how to write pure JavaScript. Think of The Guide as the whole back catalogue of a band with all their sins of the past. Whereas “The Good Parts” is their hit single.
Starting with a much cleaner slate
And here is where you come in. I don’t even want you to think about the good parts of the language itself. That can come later – if deep-diving on a language’s syntax and constructs tickles your fancy. Right now, I envy you because you have a chance to hit the ground running. And I want you, as a newcomer, to not repeat the mistakes we did to get where we are.
So next up are a few things I want to introduce to you that you can use to take the next step as a JavaScript developer. These things can help you become more effective in what you do and also help you to take part and help the community. You’re very welcome to disregard this advice. You’re also welcome to challenge it – after all, this is what new voices are about. With the speed JavaScript evolves some things I tell you now will become obsolete, for sure. But I for one am excited about these things and I am sure had I had them when my career started, I’d be much further than I am now.
First of all, where can you go to learn about JavaScript?
Unsurprisingly, this is a tricky one. JavaScript is a hot topic and a lot of people get the job to write some without wanting to understand it. This means there are terrible, spammy resources telling you the “simple” way to do something in JavaScript. Do yourself a favour and don’t fall for that siren song. Also be vigilant about “here is the quick solution” answers on the web. Often these are biased solutions that keep getting repeated to reach a quick result. If something sounds too good to be true, often that is exactly what it is.
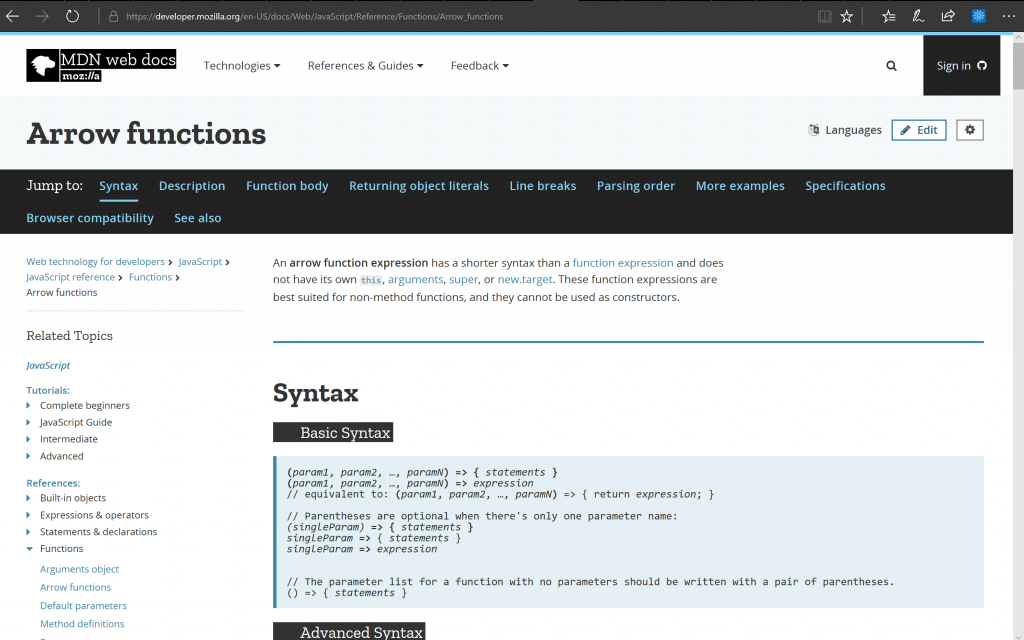
This is where the MDN Web Docs is my weapon of choice. It is a unbiased, open, very well maintained resource. It is not a Mozilla only thing, but many other players add content and help keeping it up-to-date. It is even writable – you can do edits when you find something is wrong.
The great thing about the Web Docs is that it isn’t “just” documentation. It also has code examples and detailed browser support tables for all the things it talks about. Many resources that tried to document the open web came and went. MDN prevailed.
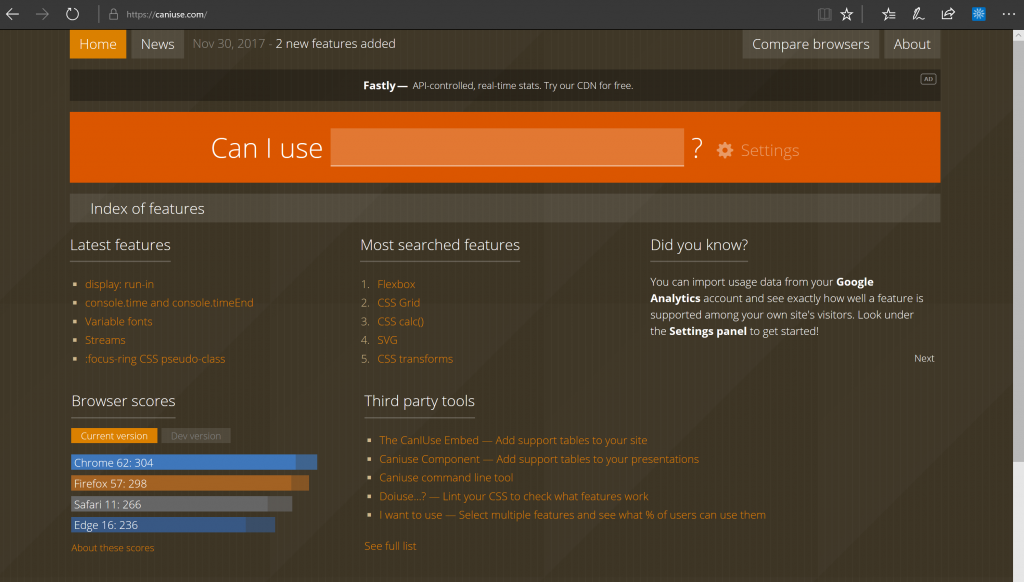
Talking about browser support, Can I use is a well-maintained resource. It doesn’t only show detailed browser support. It also links to the standard documents telling you what should happen. And it shows the quirks and problems in various versions with possible workarounds.
Browsers are much less of a problem
Talking about browsers, it is a wonderful time in that regard. We’ve had a tricky ride there. In the past, browsers were a black hole and we had no idea what magic made them work. Until browsers committed to following standards we had to know about their ideas how things should work. In essence, our career was dependent on knowing how browsers mess up. That’s easy to do, but in the long run not fulfilling. Nowadays browsers take a much more leading role in defining and inspiring standards. Browsers themselves strive to be evergreen. Non-standardised functionality is behind flags or shipped in “developer editions” or nightly builds.
The best thing is that browsers makers are available for feedback and invite you to file bugs. This has been a massive change and something we as developers should cherish. There is a lot less of “this is how it is, not much we can do” and a lot more “well, that doesn’t work, can we get this fixed”.
Browser makers also understand that developers matter. Furthermore, that a web developer is as much an engineer as somebody writing Java or C++. Engineering needs more than “throw code at us and we make it work”. We need insights into how our code performs and what effects it has. That’s why they all browser makers spend a lot of time building developer tools. These give us the insights we need to write performant and secure JavaScript.
Learning browser developer tools
It is a good idea as a JavaScript developer to get accustomed to browser devtools as much as you can. Every browser provides them and they differ in some regards, but they all give you a lot of insight. You can learn what’s available to you by inspecting objects the browser gives you in the console. You learn what happens when your page gets rendered and where the bottlenecks are. You can inspect, edit and test what the visual output of your code is and see the CSS browsers generate from it.
Moving from console.log() to breakpoint debugging
One thing that helped me a lot is moving away from a console.log() mentality to using breakpoints. Instead of having to ask for each of the things you want to know about you get so much more. Breakpoint debugging has the benefit that the JavaScript engine stops. You can then get a snapshot of what’s happening in the browser. You don’t only get the value of, for example, a variable, but you can also see the effects this change has. And you have a direct way to step through debugging your code without having to change it. One breakpoint is often worth dozens of logging requests.
It is great that we can now debug our JavaScript, but wouldn’t it be better if we didn’t make mistakes in the first place? We’re human, we get tired, we get bored, we get sloppy. That’s why it is good when we get reminders that we’re doing something wrong whilst we’re doing it. In Word processing this is the spelling and grammar check that adds squiggly red lines were we went wrong.
Linting – prevent bugs by not writing wrong code
In development, this is linting. Linters are software that analyses your code while you write it. It executes the partial code in the background and tells you when something is wrong. In the past you needed to install and configure linters yourself. These days, many come as extensions to editors with preconfigured rules. Rules that are the result of years of experts arguing and finding a consensus what makes sense. Google’s developer tools in Chrome give you similar insights. Reading through the results of linters is a good learning exercise. They not only tell you that something is wrong, but also why, what the effects are and how to fix it.
Finding an editor that makes you more effective
This is also where a good editor is a life-saver. As said before, you can use whatever you want to write your JavaScript. For me, I am amazed how much work I get done using Visual Studio Code. This editor is open source and comes with hundreds of extensions to help you with your tasks. It has linting built-in and allows for setting breakpoints in the editor itself. It contains a command line interface to do more hard-core tasks and has Git version control built in. There is something great about not having to jump from editor to browser to terminal. Of course, sooner or later you’ll have to master all three, but why not start with a shortcut?
And guess what this editor is written in? Yes, JavaScript.
When using JavaScript you will find holy wars and ideas of what editor in what configuration is the best. As there are dozens of options in hundreds of variations, you’re welcome to go down that rabbit hole. I move every few years from one environment to another and right now, Visual Studio Code makes me happy. And many others agree. It gives you a jumpstart by providing integration with build processes out of the box. It is cross-platform and lightweight compared to other IDEs with similar feature sets. And you can hack on it and extend it using JavaScript.
Publication and build processes
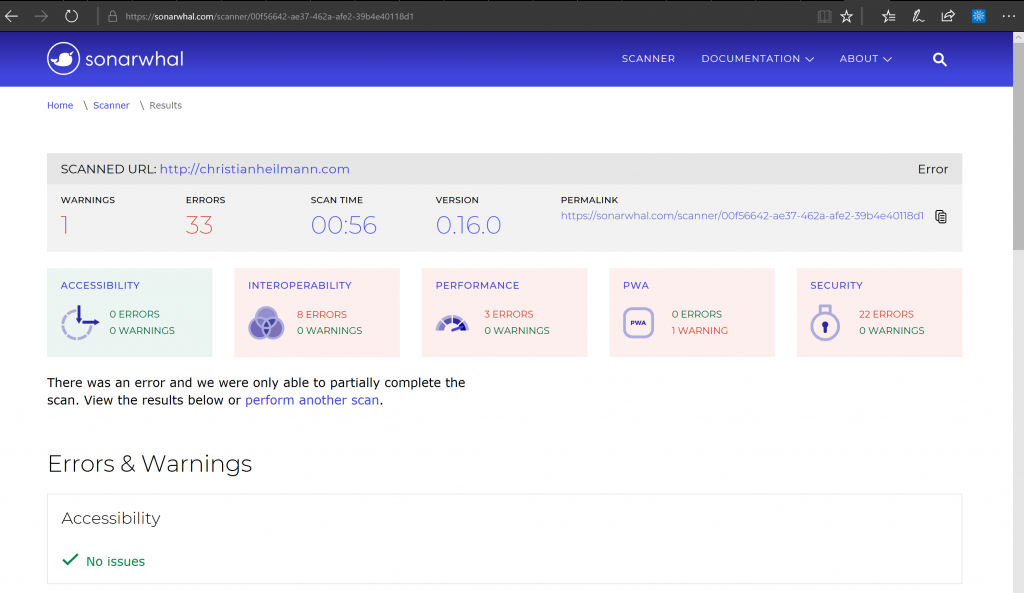
That said, editors are not the only place where linting can help. It can also be a part of a publication process. Sonar, for example is a tool that requires a URL and than tells you all the things that need improvement. This involves performance, compatibility, security and many more. A service like Sonar can act as a gate-keeper in your release process. A bug found by you is better than one reported by your users. Or, even worse, one that prevents people from using your work without you ever hearing about their problems.
Release processes are a huge part of what we follow in JavaScript these days. So it is a good idea to have it in the back of your head to get accustomed to those. A common piece of advice is to start your own project and follow best practices as you can’t break others that way. But I am not sure how helpful this is and found it rather dry and frustrating.
Should creating your first project include configuring your own server?
There is no doubt that you learn a lot by starting your own projects and running them in a professional manner. But you don’t need to start that way. I’d argue it makes more sense to start smaller. JSBin, CodePen, Glitch and other hosting communities are there for you to play and learn. They allow you to use preprocessors, frameworks and package managers to build something. You don’t get stuck setting them up and configuring your own computer over and over again. You can see if they work for you without the overhead of having to learn and un-learn something. In a job, as part of a team, it is unlikely that as a junior developer you’d be setting up the environments. So keep that for when it is necessary.
Learning materials are free and in abundance. But what’s good and what’s spam?
Talking about learning, we live in amazing times. There are almost weekly conferences about JavaScript. There are free to attend meetups. There are Slack communities, mailing lists and free online resources. Many books on the subject are free to read online. And almost all the content you pay a lot of money for to see live ends up on YouTube to watch within hours. Frankly, we have so much content that triaging it becomes a necessity. So instead of trying to follow it all, find people you trust who do a good job collecting and commenting. Then take your time to digest what is out there in your own pace. I watch talks in the gym on my phone – the average JavaScript talk burns 500 calories on a cross-trainer.
Contributing to projects and dealing with other people
Instead of starting by owning of a product, it makes much more sense to take part in existing ones. This is what JavaScript is a about these days. We’re not dealing with a language, but we are dealing with a community of developers. Many open source projects have people to help you get involved. You can get started by helping to improve documentation. You can fix simple problems the maintainers are too busy to look at as they got bigger fish to fry. And you can learn a lot by lurking and seeing what people do and how they work with each other. You also learn what to avoid and what kind of developer not to become.
As it can get messy, I’m not beating around the bush there. The success of JavaScript and the general hype around software engineering has an ugly side to it. People get into unhealthy competition and see overworking themselves as a badge of honour. It doesn’t help that many community tools value “fast an often” as a way of contribution over “good and well explained”. You will encounter terrible communication and open hostility to change and discussion.
You’re new here. Be that new person and a better one than those who annoy you
And here is my plea to you. Don’t become that person. Don’t feed the ego of those valuing telling others that they are wrong over working together. Stay calm, be kind and don’t let blanket statements and open dismissal of ideas stop you. There is a lot to choose from. No need to fill your life with more drama, when all you want is to make your mark as a creator.
We have a beautiful technology stack here and if I learned anything that change is the only constant. And today, here and now, I hope that you will be part of a change that we need.
Your happiness is more important than getting into fights over syntax, process or what framework to use. Happy developers build better products. The more diverse we become, the more we can reflect those who use our products.
And with that, I am looking forward to seeing what you do next. Thank you for going on this journey. It did me good, I hope it also will work for you.