Web resilience is about users – not a shortcut for developers
Wednesday, January 18th, 2023 at 8:11 pm
The web has replaced and outlived a lot of closed technologies because of its resilience. Its underlying technologies are simple and sturdy and one of its main design principles is to – no matter what happens – never punish the user for developer mistakes.
User needs come before the needs of web page authors, which come before the needs of user agent implementers, which come before the needs of specification writers, which come before theoretical purity.
This is why web technologies are forgiving. Enter some wrong HTML, and the browser will try to make sense of it and automatically close elements for you. Enter some invalid CSS, and the line of code gets skipped.
Endangered species: the indie web publisher
This is excellent for end users, but it always felt wrong to me when it comes to building things for the web. Sure, the web should be a read/write medium and anyone consuming it should also have only a small step to take to become a publisher on it.
But let’s be honest: most publishing on the web doesn’t happen by writing HTML and CSS, but inside other systems. You can still run your own server, set up your own blog and all that, but the majority of people who put content on the web don’t ever touch any code or own any of the infrastructure their content is published on. Whether that’s a good thing or not is irrelevant – we lost that battle. And whilst we are always smug when the likes of Twitter or other platforms get into trouble, it still means a lot of people adding to the web will go somewhere else. To another product, and not start writing HTML or hosting their own blog.
It works, why care?
My problem with a forgiving platform is that it makes it a lot harder to advocate for quality. Why should a developer care about clean HTML and optimised CSS when the browser fixes your mistakes? Even worse, why should HTML and CSS ever be respected by people who call themselves “real developers” when almost any code soup results in something consumable? There are hardly any ramifications for coding mistakes, which means that over the years we focused on developer convenience rather than the quality of the end result.
This happens in language design and implementation, too. JavaScript adds semicolons automatically to your code when you forget to add one at the end of an instruction. PHP, often the butt of jokes when it comes to consistency and code quality does not and flat out refuses to compile. I never understood why I wouldn’t add a semicolon, after all I also end sentences with a full stop. But people are loud and proud about not adding them and relying on the engine to do it for them. When ECMAScript got its standard discussions many “10x developers” were incredibly outspoken about not using semicolons as a sign of change and trusting the runtime to do these things real programmers shouldn’t worry about.
Another thing that irks me is that IDs in HTML automatically become global JavaScript variables. Developers relied on that convenience for quite a while instead of getting a reference to the element they want to interact with. This convenience also represents an attack vector to allow for DOM clobbering and it is not alone in that. The web is ripe for attacks because of its lenience in what developers can throw at it.
HTML and CSS are compilation targets
The main difference to the web development world of the past and the web of now is that most development happens with abstraction layers in between. HTML and CSS isn’t written by hand, but it is generated. JavaScript isn’t in some files, it is in modules and we use package systems to create bundles. What ends up in the final product isn’t the source code any longer. There are many steps in between. This adds another complexity as it gives developers the false impression that the optimised source code also results in great final products. In reality abstractions often result in generic, bloated code. Code that doesn’t look terrible to us, as it does show something useful and our fast connections and great computers show us a smooth experience.
It feels like we never embraced the alien that is the web to our software world. In almost any other environment you write code, and you compile optimised code to a certain environment. On the web, compilation wasn’t needed, but we ended up in a place where we do it. And we compile to the unknown, which in itself doesn’t work.
Compiling into the unknown
Let’s remember that no matter what we build our products with, what will end up on your end user’s computers is HTML, CSS and JavaScript. Or tons of JavaScript executing whatever code you want in Webassembly. The end user’s device, connection speed and the way they interact with your product are utterly unknown to you. That’s why our goal should be to create clean, lean and excellent web code that is resilient to any and all problems that could happen on the end device. Going back to the main design principle of the web where the user should get the best result and be our main focus. And not how easy it is to build a huge system in 20 minutes with x lines of code. Just because the resilience of the web means our code does not break doesn’t mean it works.
Tooling tells us what’s wrong – but who listens?
I work in developer tools of the browser which are excellent compared to what I had to work with when I started. I find myself often at a loss though what I could still give developers to make it even more obvious that what they are doing hurts end users. Open any web product and take a look at the issues tool in developer tools and you are greeted by a deluge of problems that can be a barrier for end users and – even more annoying – are easy to avoid.
You even see squiggly underlines in the DOM tree when something is wrong – much like Word shows when you are making writing mistakes.
If you use certain extensions in editors, you even get that live while you are writing your code with explanations why what you do is a problem and how to fix it.
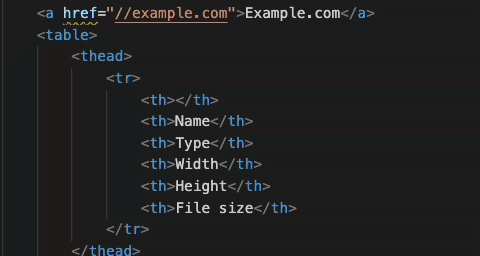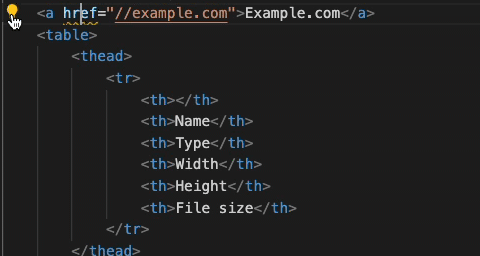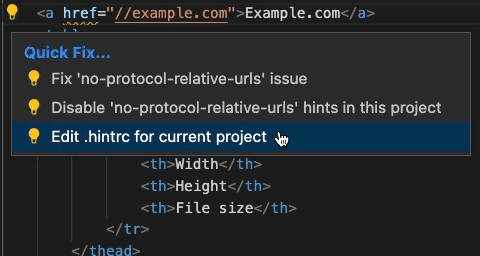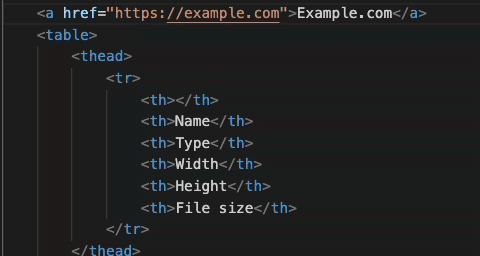
And yet, what’s on the web is to a large degree terrible. Which brings me to the main question I am pondering: is the web development stack and environment too lenient? Should developers have a harder time making obvious mistakes instead of getting away with them? I remember when XHTML was an idea and a single wrong character encoding would have meant our end users can’t access a web site. That was a clear violation of the main guiding design principle of the web. But in a world where we do convert source code to web code anyways, shouldn’t our bundlers, frameworks and build scripts be more strict and disallow obvious issues to get through and become something the browser has to deal with? We do write tests for our code, shouldn’t a system that checks your final product for obvious issues also be part of our delivery pipe?
Should bad code be something we always expect?
Being lenient with developer error is incredibly ingrained in our work. Currently I am working on a JSON display in the browser. JSON was a much more lightweight and straight forward replacement for XML and it is in essence writing JavaScript objects. And yet, looking around for demo APIs to throw at our JSON viewer, I found an amazing amount of broken JSON. My team, seeing developers as our end users, kept looking for ways to automatically fix broken JSON to at least display something instead of just an error. We’ve been conditioned to expect broken code and invalid data and try to work with it. That does not sound like a good idea to me. Maybe it is time to take a stand and build systems that tell developers flat out when they are making mistakes that don’t have to be on the web.