A code snippet to scrape all headings and their target URLs from a markdown generated page
Friday, February 19th, 2021 at 7:54 pmWhen you use Markdown to write your documentation most static page generators will generate IDs for each of the headings in the document to allow you to navigate directly to them.
Markdown: ## Gerbils and other rodents HTML: <h2 id="gerbils-and-other-rodents">Gerbils and other Rodents</h2> |
To go directly there you can then use https://example.com#gerbils-and-other-rodents if you published at example.com.
The other day I was asked to create a list of all the links in the What’s new in Devtools 89 document, which is generated from Markdown. The list should be the text of the headline followed by the full URL to get to that part of the document. This was to batch generate some shortURLs from them.
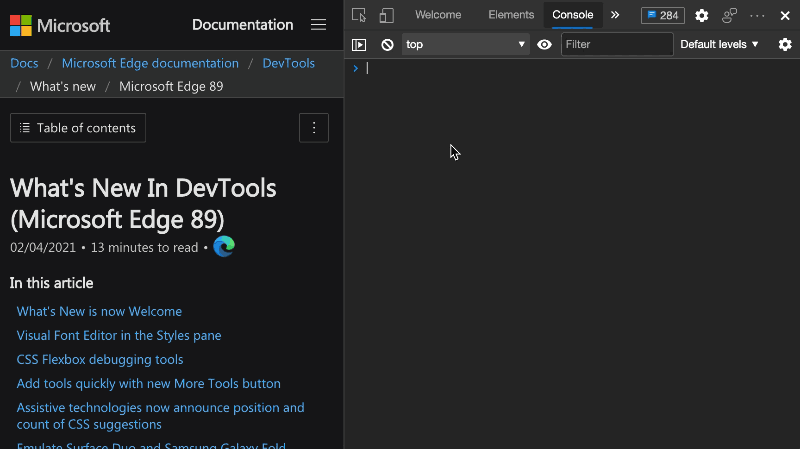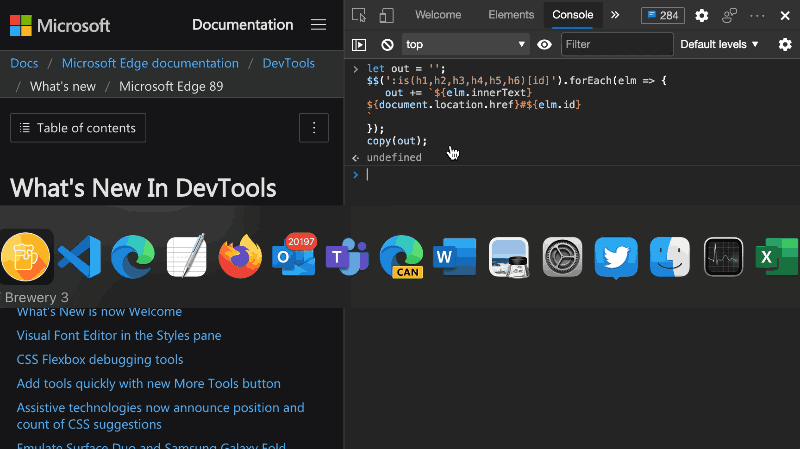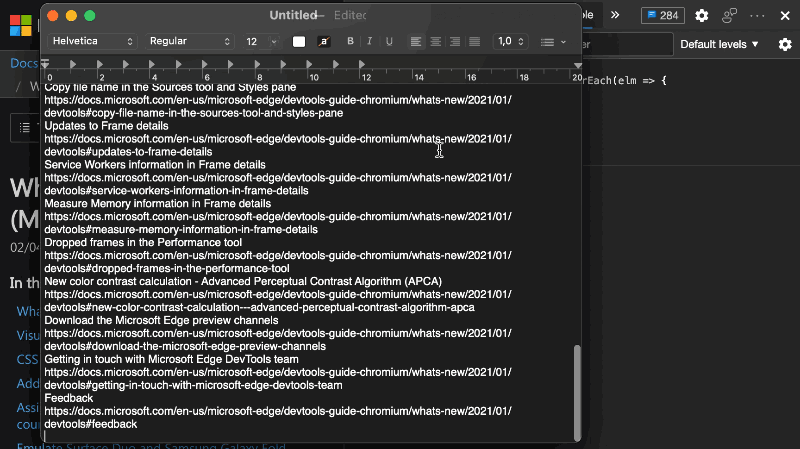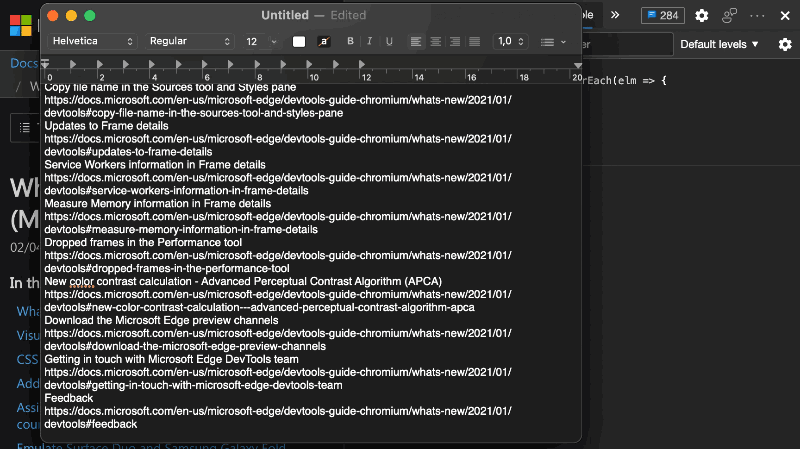
I am pretty sure there are a lot of clever ways to do that by scraping but as I like my browser environment, I just used the Console to do that. Here’s the script that you can paste into the Console:
let out = ''; $$(':is(h1,h2,h3,h4,h5,h6)[id]').forEach(elm => { out += `${elm.innerText} ${document.location.href}#${elm.id} ` }); copy(out); |
You can see it in action in the following GIF:
The next step was to store this as a Snippet and next time I just need to run that.