Always bet on HTML – being misunderstood
Monday, July 6th, 2020 at 11:21 amA few weeks ago Chris Ferdinandi wrote an ode to HTML called Always bet on HTML in which he once again praises the benefits of HTML as a base for your products on the web. He is correct and makes a lot of great points. However, we made these points for 20+ years and people keep underestimating the benefits of starting with a solid HTML base. Maybe it is time to look at the reasons why people might be less enthused about HTML than Chris (and me) are.

HTML is not a programming language
HTML is dumb – which is a good thing and one of the cornerstones of its resilience and sturdiness.
Programming languages allow you to use logical constructs like loops and conditions. They also have a concept of variables and you can do calculations on them. You can react to input and convert it before you display results. They need some sort of runtime to execute all of that in.
HTML doesn’t have any of that. Which is OK - it was never meant to have that. But – for some – this makes it a less interesting skill to learn. That might irk us, but it is something we have dealt with since the arguments around the value of HTML started.
HTML is a markup language you use to describe what something is. Then you need to rely on another piece of software like a browser to do something with that information. You don’t install that browser or control it like you would control a runtime on your server. You have no way of knowing if it succeeded or not – all you can do is trust in the platform and your users’ unknown setup.
Support can be sketchy and HTML doesn’t tell you that
That’s why HTML comes with fallback options. Alternative text for images. The inner content of a canvas element to show when canvas isn’t available. There is a problem with that though – when it doesn’t work.
I wrote about a problem like this seven years ago . When you add an image to your HTML document things can go wrong. If the image isn’t avaible or in an unsupported format, the browser displays a broken image and the alternative text. You can even track that in JavaScript – as the image throws an error.
When you try to play a video with a non-existing codec the alternative content in the video element doesn’t show up – all you get is a broken interface. Content inside the video element only shows up in browsers that don’t support it (i.e. none these days). To give your users a great solution you need to progressively enhance. You show an image linked to the video, test in JavaScript if the video could play and then replace that image with a video element. Exactly the opposite that HTML should be about.
The problem goes deeper though. When it comes to budgets, the focus in most cases is on delivering a gorgeous product. That is much more important than resilience and fallback content. The product design shows a colour picker in the companies’ style. Your solution shows a different one or a form field as a fallback.
For us as lovers of the web and developers that’s great and clever. Those who sign off the product cheque think differently – they didn’t ask for that and it smells of extra work. This should be a problem we tackle – not developers who need to stay in their allotted time and deliver.
HTML and browsers are forgiving
One of the main strengths of HTML is that it is resilient. This wasn’t always the case and often you had to do weird things to make even HTML and CSS work in browsers.
Back in the days, for example, older browsers made the error of rendering whitespace in HTML. If you styled a list with background colour there were lines between the items. There were a few fixes for that, but a big and silly one was to use the following markup abomination :
Nowadays, though, the parser is forgiving and will do its very best to guess what you meant with faulty HTML. It closes tags for you, it moves wrongly nested elements out of the parent element and it happily renders <ilovebacon> as a <div>.
This was a pragmatic move by browser makers as the web is full of horrible markup. The problem is that it also is a carte blanche for any developer not to give a hoot about the quality of their HTML. In my 20+ career as a web developer I kept running into people who learned HTML in 1998 and never bothered to keep up. Table layout works and browsers can’t break the web so they will keep showing them. Why bother changing my ways as a developer then?
I understand this is glib. But when you have a 9-5 job as the maintaining web developer of a legacy web site with thousands of pages you have a different view. You are happy to sit your time out, hope nothing breaks and not change the world.
So what I am saying is that as HTML can not fail, people don’t take it as serious. A stack that throws errors in your face making it obvious that you’ve done something wrong gets more attention. Semantic and clean HTML has numerous benefits, but many of them aren’t obvious if your goal is to “build things that don’t appear broken – as quickly as possible”.
HTML is “too open”
There is no doubt that we expect more from web products than we did in 1997. The web has become the mainstream platform for media distribution. This clashes with some of its ideas.
For example, when it comes to video display on the web the video element gives you a way to download the video in case it doesn’t show. As a video content provider you don’t want that. You want people to go to your product and consume the video there alongside your ads. To meet your business goals, you need to work around HTML’s idea of making everything available. Many video platforms offer video download as a carrot to sign up for a full account. And the business folk in your company rely on the developer to safeguard that. Is this good? Not in my book, but this is how our market works.
Only generated HTML scales
HTML is excellent for marking up a single document. It shines when you know what the content is that you’re turning into a web document.
But how often does that happen? Most of the time our products are CMS driven. The content comes either from editors or – in a social product – from our users. Even when we know the content there is the problem of scale. It is fun to create a valid, sensible menu in HTML:
It is less fun though that you have to change it for every page in the site. And that multiplies when more pages and child pages come into play later down the line.
We invented a few things that helped solving that problem. IDEs with include functionality and clever search and replace were one of them.
The first solutions I used were frames and then server-side includes. The former allowed me to maintain one menu file but meant that you needed to set target attributes on each anchor. The latter had an absolutely bonkers syntax and needed Apache to run (so I couldn’t test my pages on my file system without installing it).
A much easier way is to use a scripting language that deals with the necessary logic and renders out HTML. Including this JavaScript in any document in the site laid out in pages renders the above HTML and automatically shows the current document without a link around it.
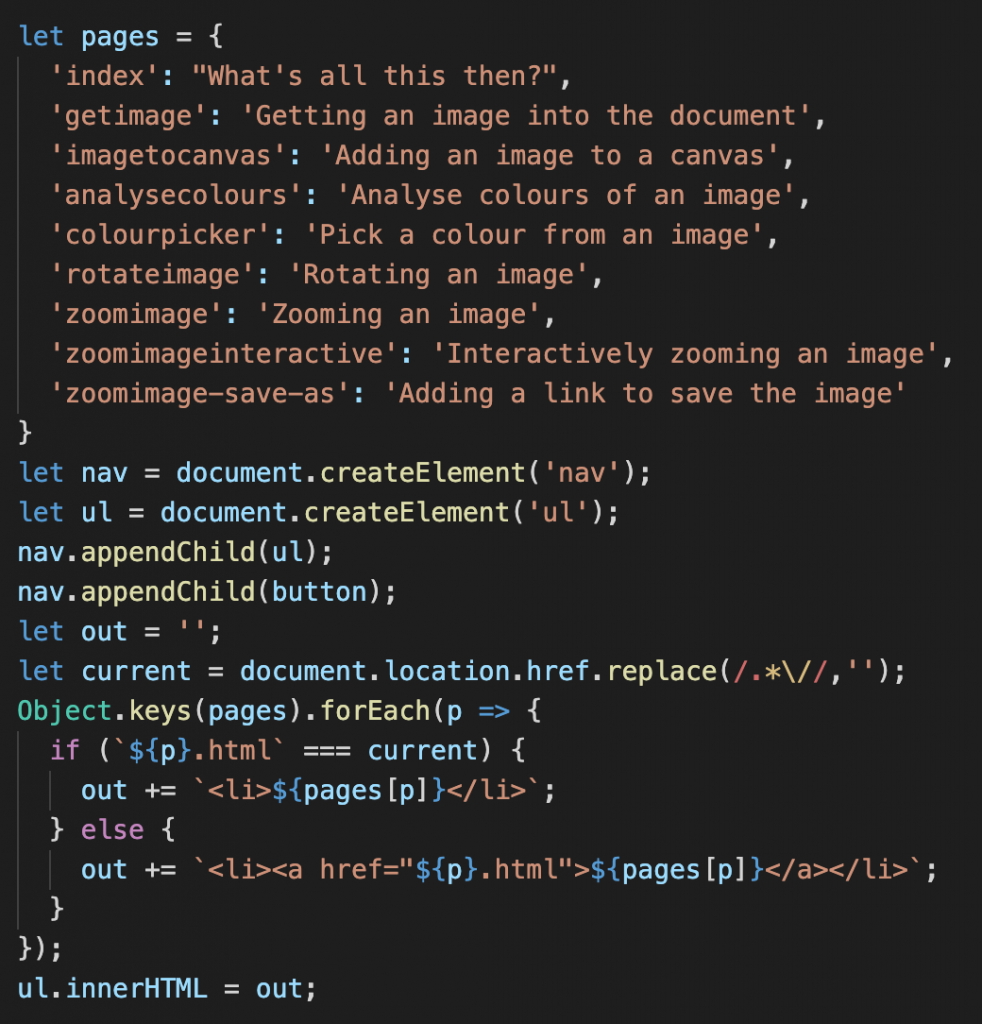
Regardless of language you used for similar functionality, one thing cemented itself in the developer community mindset: HTML needs help to be useful and to scale to larger projects. It is something you generate using a “better” language.
Form styling is a mess
Traditionally the biggest thing people complained about in CSS (other than vertical centering) is that it is hard to style form elements. The purist in me is OK with that – why shouldn’t end users realise that something is a password field? But Flash allowed you to style forms any way you want to, so the web should, too. The problem was that form elements looked dated and in some cases even hard to use (example: scaling radio buttons for mobile). Furthermore, even in modern browsers it needs some in-depth CSS knowledge to reliably style form fields. Which is a shame as the new(ish) functionality of forms like error handling make a lot of basic JavaScript checking obsolete.
The good news is that things are happening. The Edge and Chrome team did a lot of work lately to clean up the UX of form elements of Chromium and even started the Open UI project to scale these efforts.
In any case, the problem of form styling results in many a <div> with an event handler instead of a <button>. Many complaints stem from legacy browsers and pains long forgotten, but why take the chance when frontend frameworks come with snazzy interaction components that even look “modern”?
JavaScript can patch anything
The biggest problem with making people understand the power of simplicity that is HTML is that JavaScript is too damn useful.
Ever since the days of DHTML, JavaScript gave developers a sense of control over the problems of HTML and CSS support in browsers. I remember writing scripts to test for document.layers or document.all support and render out different interfaces that way. JavaScript seems the perfect way to patch things and make them work independent of browser or support of new technologies. You could even argue that our practice of “polyfilling” was counterproductive. Polyfilling meant you use JavaScript to give functionality of upcoming standards to older browsers right now. If you already need JavaScript to make something work why not use it from the get-go as HTML/CSS support isn’t reliable? Of course polyfilling means you only use JavaScript in non-support environments. But the presence of JavaScript gives a message to those who only want to get things done that it is probably a safer bet to always use it.
We’ve always been impatient and when something cool that is a web standard wasn’t supported in all major browsers yet, JavaScript came to the rescue. Often by the time all browsers caught up the thing wasn’t even interesting any longer as we moved on to the next new thing to chase.
In summary
On the surface, the choice of HTML as the base of your web product should be blatantly obvious. There are a few valid and human things that make people not agree though.
- A sense of wanting everything shiny and new right now.
- A history of sketchy browser support.
- A lack of simple customisability of the final result.
- A false sense of being able to fix everything with JavaScript.
The biggest obstacle to embracing HTML is that people don’t want to give up control. JavaScript gives you a sense of control – code that you wrote naturally is perfect, right? In reality though, JavaScript support is flaky. Browsers not supporting features, flaky network conditions and blockers are just a few things that work against you. We’re working hard to make network issues not be a problem any longer. But in essence, relying on JavaScript always means to rely on your users’ environment – something you can’t control.
That said, to me the argument of HTML vs. JavaScript is boring and we’ve spent years running in circles around it. HTML has come leaps and bounds and every new functionality doesn’t only come as a “trust us, this works in browsers” but also with an API to react to non-support or problems and – more importantly – styling hooks.
JavaScript is immensely powerful and – used well – a boon to the experience of our end users. Storing content with service workers, lazy loading things with IntersectionObserver, there are numerous examples of things we can’t do in HTML, but are great customer experiences. Truly, the biggest plus of JavaScript solutions is that you can react to the environment and only deliver what is needed at the time. But that doesn’t mean you can’t render that on the server side in JavaScript after doing a simple test on the client.
The job we have now is to battle some of the old prejudices against HTML with facts and good examples. Not by telling people off for relying on JavaScript. Often the best way is to ask why they chose to do that. If there is a lack of education or HTML knowledge, we can follow up with good resources. I’m pretty sure the image of the “I don’t care about end users, the only thing I care about is developer convenience” code-Bro isn’t as common as we think it is.