Showing off your presentation slides with slideshare, PHP and a bit of JavaScript
Wednesday, October 31st, 2007First of all, I am a big fan of slideshare, a web app that allows you to upload presentations in powerpoint, open office or PDF and share it on the web. Slideshare converts the presentation (sadly enough not 100% when it comes to fonts and kerning :-( ) and people can comment on them, there is a text version of all slides and you can embed the slides in your blog or other sites.
When I checked my slides I had a look at the API of slideshare but I am always a bit bored with having to go through a developer ID and then do everything on the server. That’s why I put on my “ethical hacker” hat and took a look at the RSS feed of my slides and found everything I need there! If you look at the source of the feed you’ll see that it contains not only the titles and descriptions but also the media code, in this case the HTML to embed the right flash movies.
Taking this information it is pretty easy to build a viewer that allows people to click through all your presentations without having to leave your site. This can look something like this:
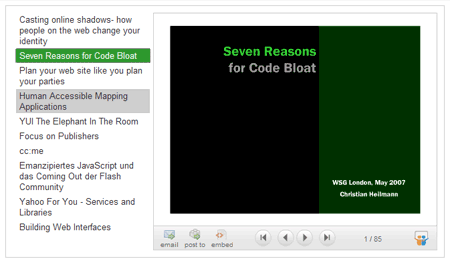
When JavaScript is available this will be the look and feel and functionality. When JS is turned off all you’ll get is an unstyled list of links pointing to the presentations on slideshare.net.
You can check the slideshare show in action and get a zip to download and use on your site if you don’t want to know how it is done. If you do, read on…
The code necessary is really easy and done in about 70 lines. Let’s go through it bit by bit. I am using PHP4 together with cURL, DOMXML and some JavaScript using the YUI.
<?php $url = 'http://www.slideshare.net/rss/user/cheilmann'; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $slides = curl_exec($ch); curl_close($ch); |
It starts with the URL we want to load and a CURL call to pull this file and store it in the variable $slides.
$slides = str_replace(‘slideshare:embed’,’slideshareembed’,$slides);
$slides = str_replace(‘media:title’,’mediatitle’,$slides);
$xml = domxml_xmltree($slides);
To make things easier (as DOMXML is a terribly hacky piece of kit – much easier with PHP5 and SimpleXML that one) I rename the namespaced attributes in the feed containing the embed code and the title of the media to simple elements and create an object collection from the XML using domxml_xmltree.
$json = array();
$slidesharelist = ‘’;
$links = $xml->get_elements_by_tagname(‘link’);
$img = $xml->get_elements_by_tagname(‘url’);
$titles = $xml->get_elements_by_tagname(‘mediatitle’);
$embeds = $xml->get_elements_by_tagname(‘slideshareembed’);
Then I need to preset an array to contain the embed code for each slides and a string to contain the list of links pointing to presentations on slideshare. I use the get_elements_by_tagname method of DOMXML to get arrays of the different bits of content that I need from the RSS feed.
foreach ($embeds as $key=>$el) {
$l = $links[$key+2]->children[0]->content;
$t = $titles[$key]->children[0]->content;
$slidesharelist .= ‘$emb = $el->children[0]->content;
if(strpos($emb,’
preg_match_all(‘/.*(
$json[]=’‘’.$obj[1][0].’‘’;
}
?>
By looping throught the “embeds” array I assembling a list of links pointing to the different presentations and add the embed code to the JSON array. I need this one later to show the different flash movies when visitors click the presentation links. Notice that I need to skip the first two LINK elements as that is the one pointing to the main URL of the RSS feed. For some reason the order of embeds was different on my localhost and my live server, which is why I added that extra if statement. Annoying, that.
That is all the PHP we need! Now it is time to make it pretty and add the rest of the HTML.
As it is hacky enough to mix PHP and JavaScript I put all the CSS fun in an own document and only add the logo of the RSS feed as the background of the slideshow container. The markup is a main DIV with an unordered list that gets the HTML assembled earlier in the PHP script. This shows the links but doesn’t do the dynamic showing yet. For that we need JavaScript.
That’s all, except for putting the data from the RSS feed into a “slides” array and closing the module pattern.
Together with the right style sheet this is enough to have a clickable list of your latest presentations on slideshare. Enjoy.

